異常検出
異常または外れ値検出を使用して、標準的または期待する動作から逸脱するイベントやデータポイントを識別します。
データ内の外れ値を識別することは、様々なシナリオに対する早期の指標として機能し、経営陣やアナリストが潜在的な問題を発見したり、戦略の策定、パフォーマンス向上に関連する外部要因を把握するのに役立ちます。
Analytics Plus Cloudは、RPCA(ロバスト主成分分析)などの機械学習アルゴリズムや、外れ値を検出するための様々な統計モデルを導入しています。
ビジネスユースケース
- 電子商取引
企業が売上の急激な増加や減少の理由を把握するのに役立ちます。
短期間でカートの放棄率が急上昇した場合、チェックアウト時のWebサイトに問題がある可能性を示唆している可能性があります。 - マーケティング
Webサイトのトラフィックやサインアップの増加、減少につながる根本的な理由を把握することに役立ちます。 - ヘルプデスク
サポートチケットの送信数の急増や、注意が必要な製品を特定できます。 - セキュリティ脅威検出
サイバーセキュリティにおいて、セキュリティ上の脅威を示唆する可能性のある異常なネットワークアクティビティやパターンを識別するのに役立ちます。
留意点
- 異常検出機能は、数値データ型のカラムに対してサポートします。
- RPCAモデルでは異常を識別するために最低6つのデータポイントが必要であり、統計モデルでは最低7つのデータポイントが必要です。
- すべての種類の折れ線グラフと棒グラフで異常または外れ値の検出がサポートされています。
- 異常は複数のY軸に適用できます。
データに異常検出を適用する
- 異常検出を行う対象のレポートを開きます。
- 編集画面で、[分析]→[異常値]をクリックします。
![異常検出オプション]()
または、レポート画面右上の[設定]アイコンをクリックして、[分析]→[異常値]をクリックします。
![異常検出代替オプション]()
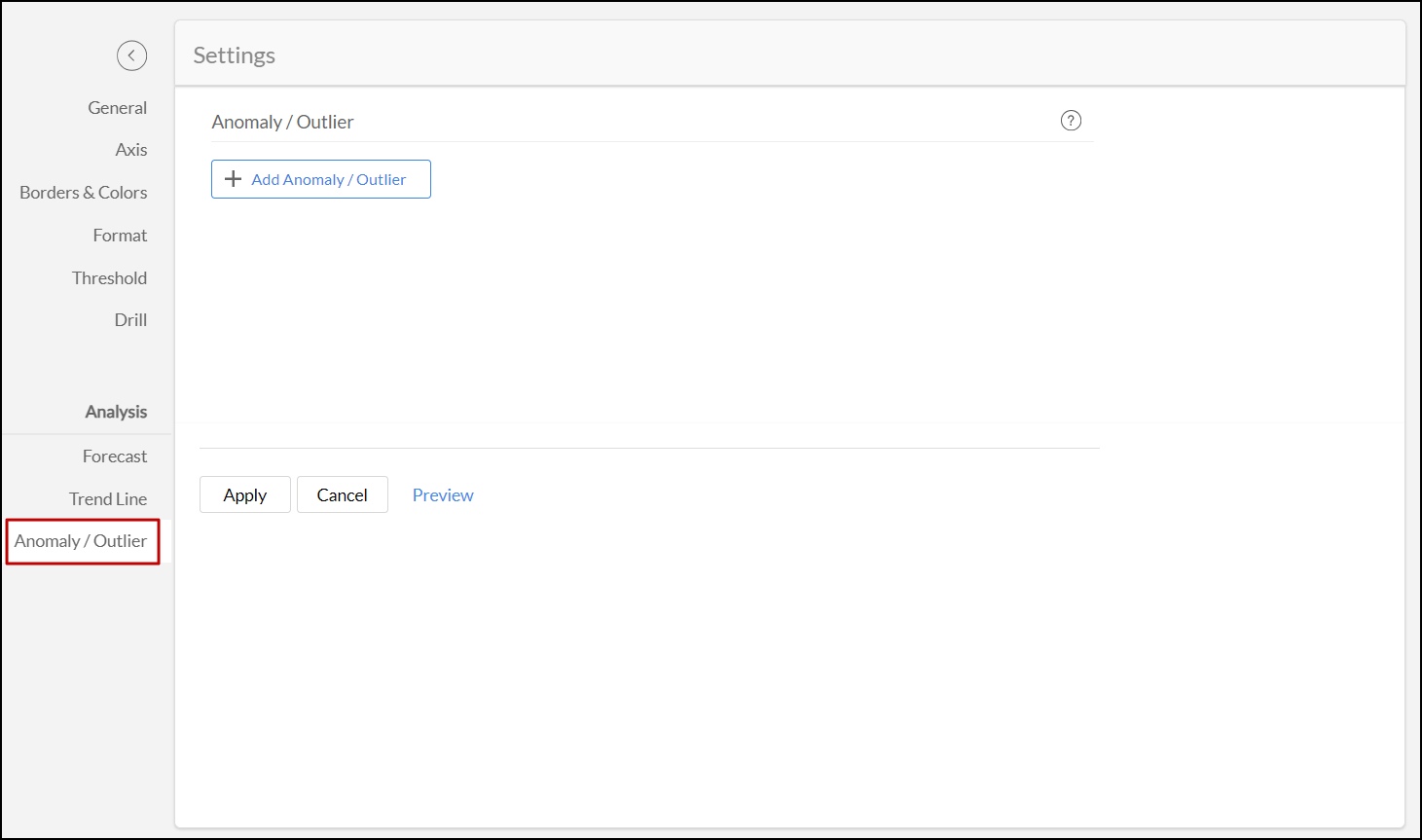
- [異常値を追加する]をクリックします。
- 異常を検出するカラムを選択します。
- 異常値の名前を入力します。
- 外れ値を検出するために使用するモデルを選択します。
各モデルについては、本ページの下部も参照してください。- RPCAモデル
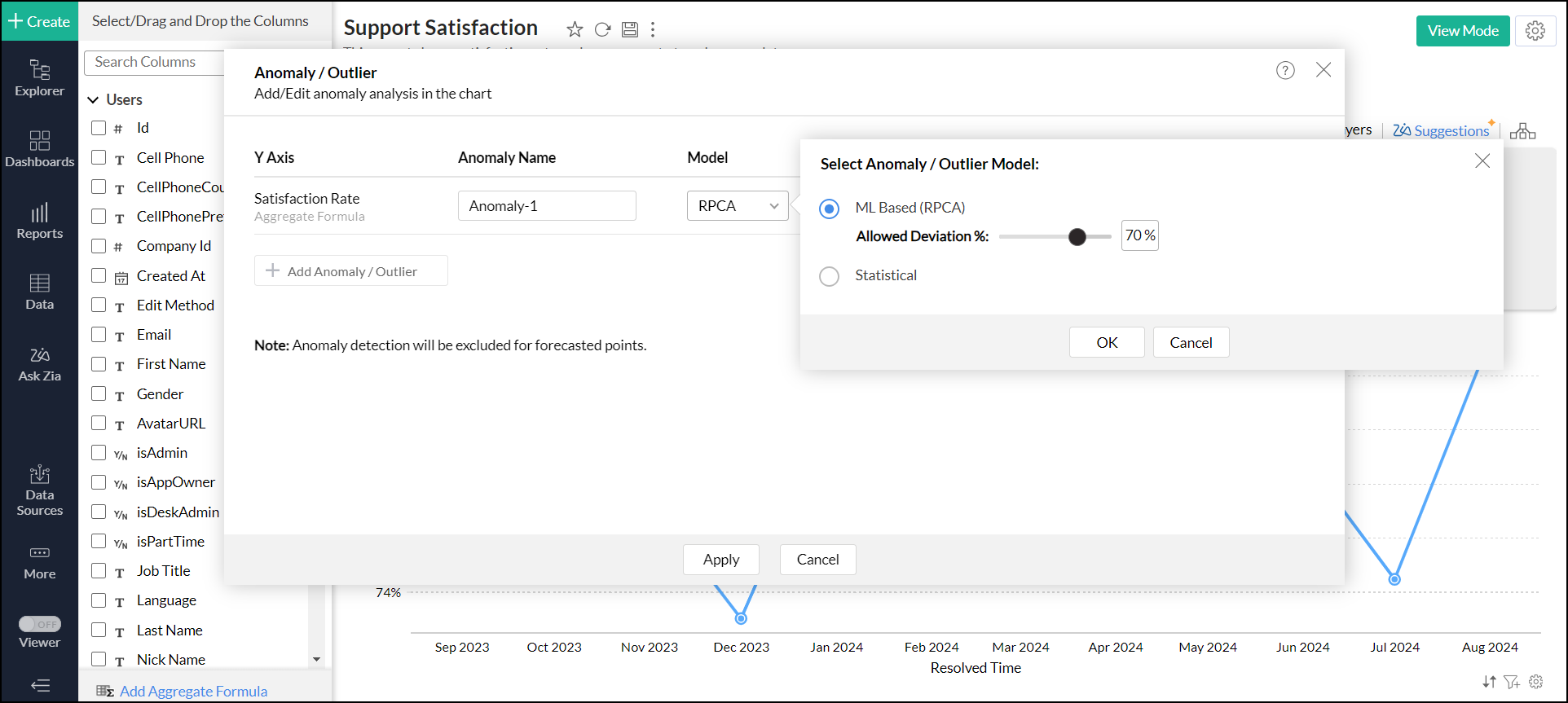
RPCAモデルの偏差パーセンテージを調整します。
偏差パーセンテージを下げるとデータの感度が高まり、わずかな偏差でも外れ値としてマークされます。
偏差パーセンテージを大きくすると感度が低下し、外れ値を見つける際の選択性が向上します。
デフォルトの偏差パーセンテージとして70%が設定されています。![RPCAモデル設定]()
- 統計モデル
外れ値を識別するために使用する統計モデルとしきい値を選択します。
データ分布に基づいて統計モデルを選択する方法![統計モデル設定]()
- RPCAモデル
- 特定の境界内の異常を識別するために方向(両方、上、下)を選択します。
デフォルトでは、「両方」が選択されます。- 上
統計モデルに対して上限しきい値設定のみが表示されます。 - 下
統計モデルに対して下限しきい値設定のみが表示されます。
- 上
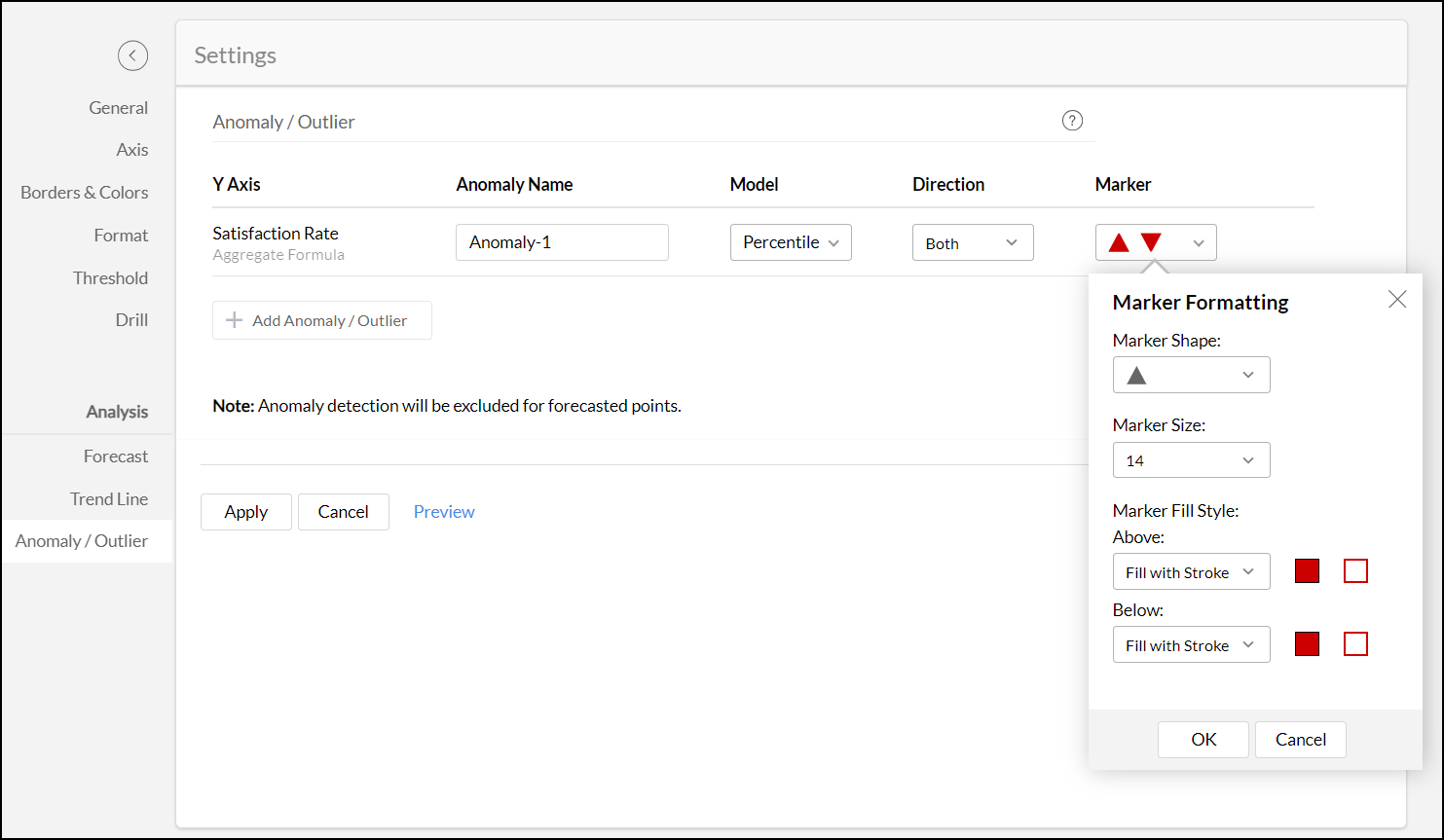
- 必要に応じてマーカーの形状やサイズ、色ををカスタマイズします。
![マーカー形式設定]()
- [適用する]をクリックします。
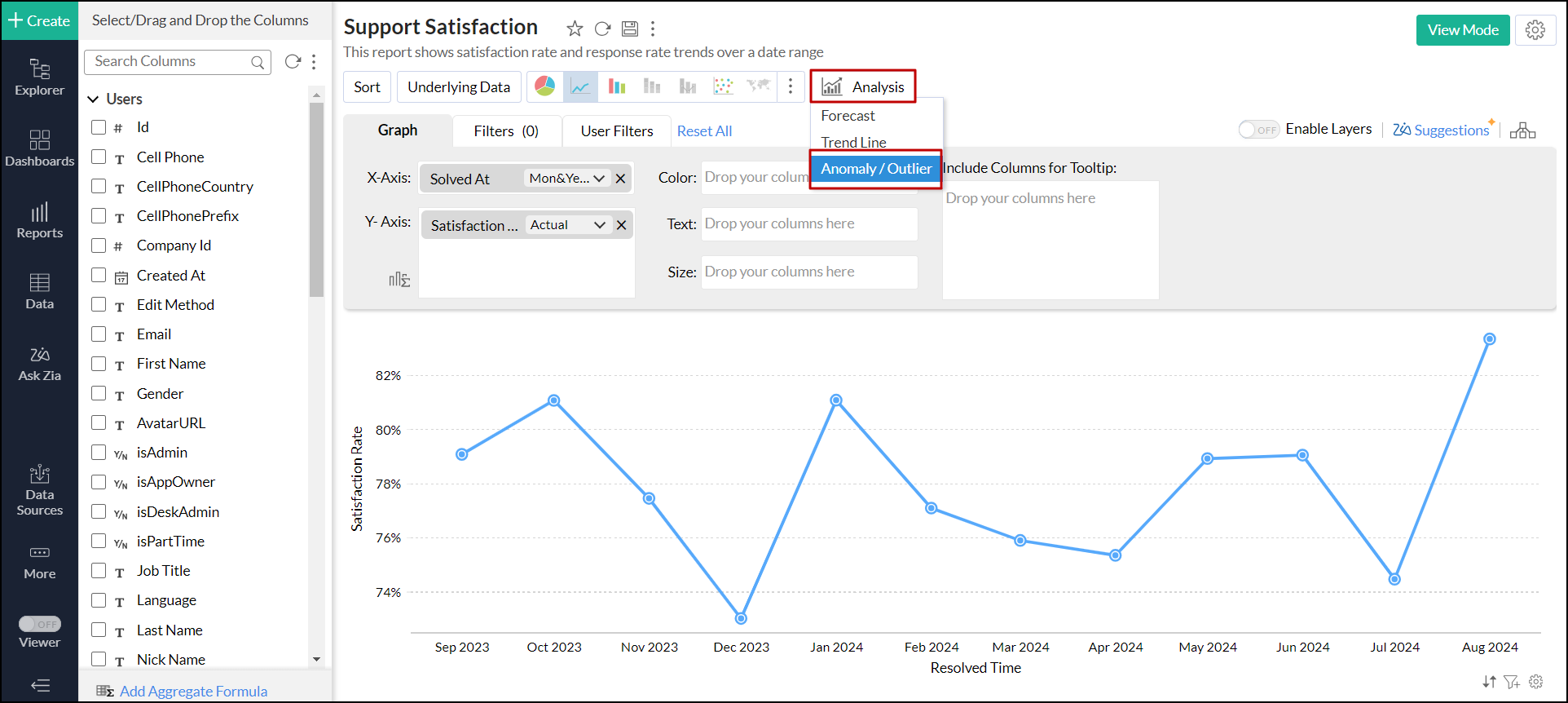
異常に関する情報
外れ値として識別されたデータポイントはマーカーによってマークされます。
マークされたデータポイントをクリックすると、異常に関する詳細情報が表示されます。
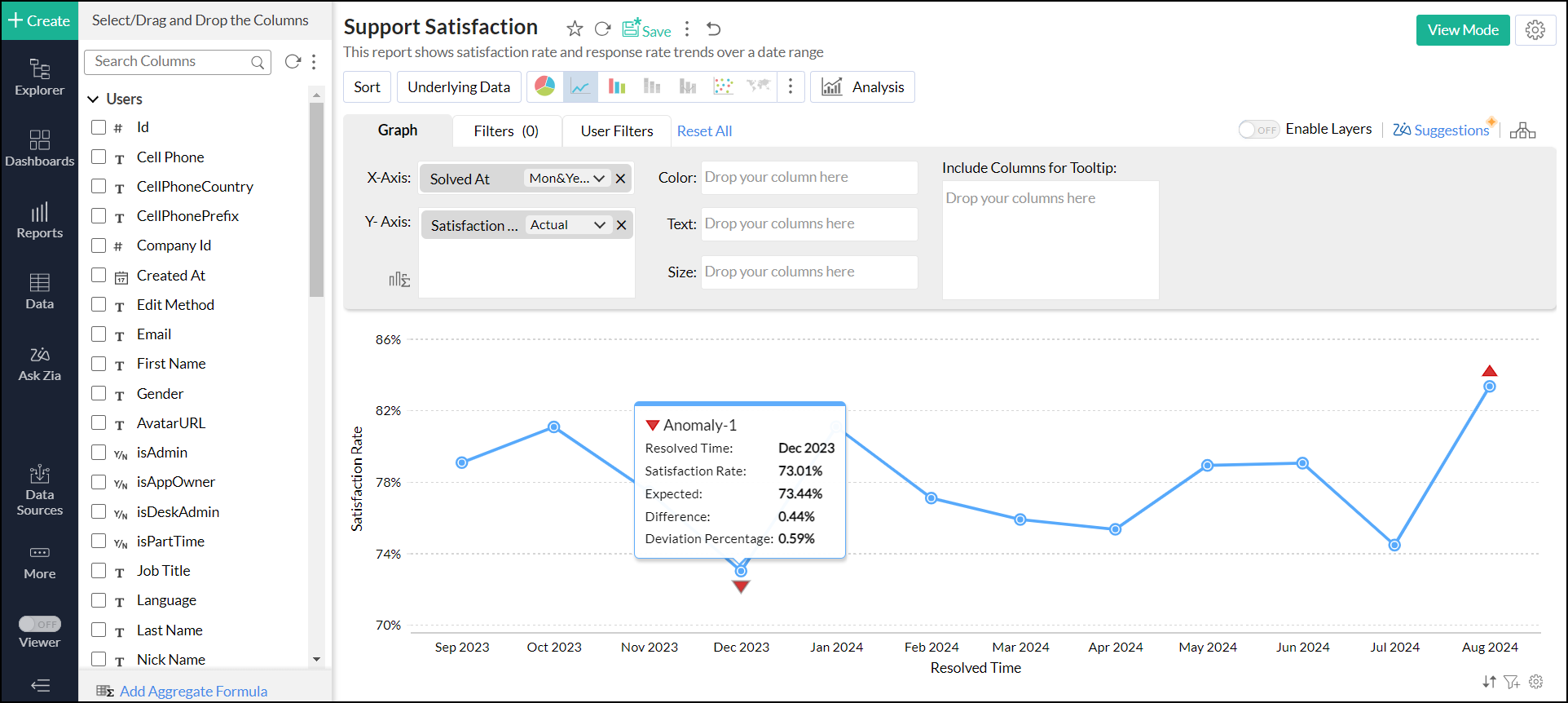
- 期待値
基準となるX値に対して、選択された異常検出方法によって算出されたY値。 - 差異
異常の実際の値と予想される値の差 - 偏差パーセンテージ
予想値に対する偏差のパーセンテージ
機械学習モデル - RPCA(ロバスト主成分分析)
このモデルは、季節パターンと時間的側面の両方を考慮して、時系列データ内の単一変数データセットの異常を識別します。
また、許容される偏差のパーセンテージに基づいて異常を識別します。
偏差パーセンテージを調整することにより、アルゴリズムは大きな偏差を示す異常を検出できます。偏差の範囲は0%から95%まで変更できます。
デフォルトでは、許容される偏差率として70%が設定されています。
このモデルは、時系列値で集計された測定値に関する異常を検出するのに最適です。
統計モデル
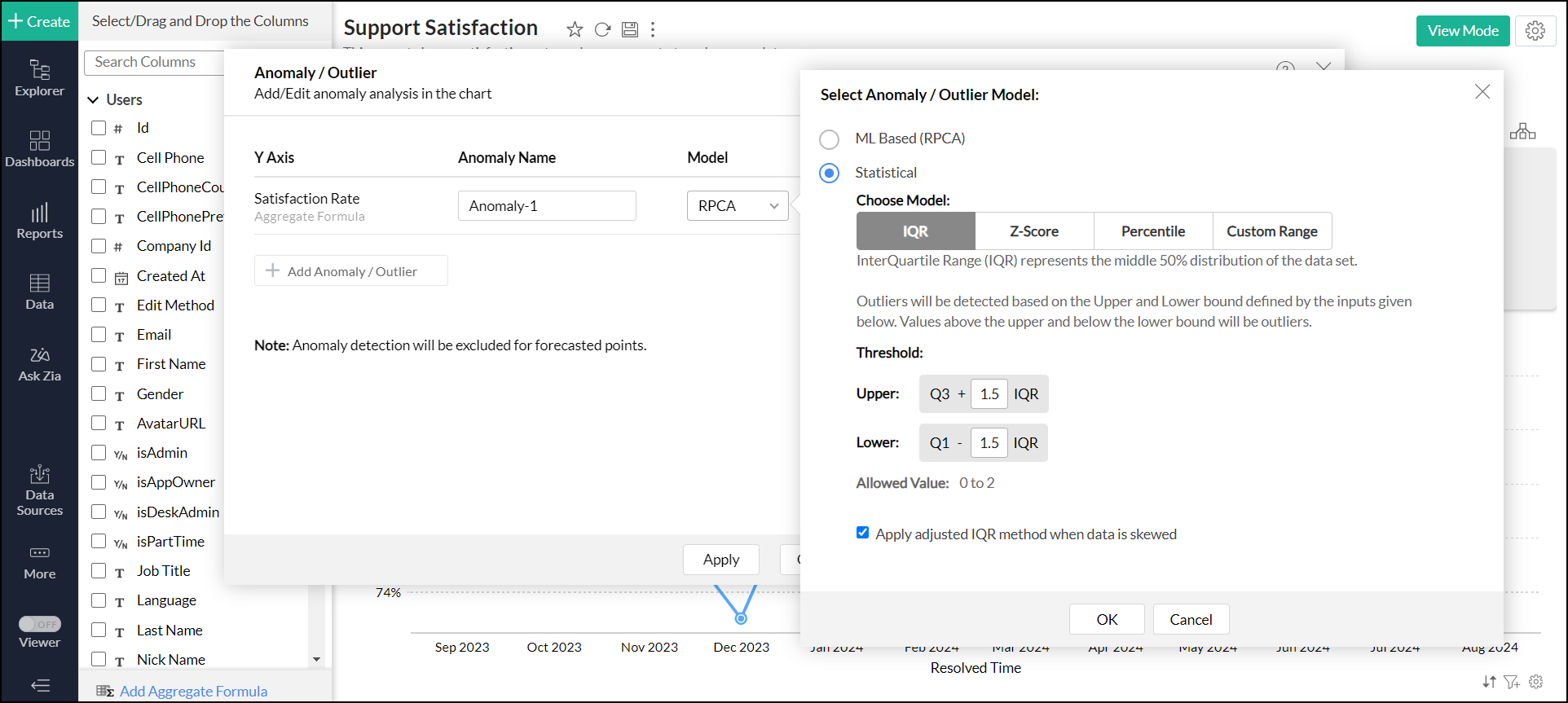
四分位範囲
四分位範囲(IQR)は、データセットの中央の50%が含まれる範囲を表す統計的分散の尺度です。外れ値はこの範囲に基づいて計算されます。
IQRは、第3四分位数(Q3)と第1四分位数(Q1)の差として計算されます。その後デフォルトのスケール値1.5にIQRを掛けて、上限と下限の範囲(しきい値)を決定します。しきい値は、データの分布に基づいて調整できます。
偏った分布を持つデータの場合、調整されたIQR法が適用されます。
Zスコア
Zスコアは、データポイントがデータセットの平均から標準偏差の観点でどれだけ離れているかを示します。
デフォルトでは、Zスコアが3を超える場合、データポイントは外れ値としてマークされます。
外れ値を検出するためのしきい値として、Zスコアが±3に設定されることが多いです。つまり、平均値からいずれかの方向に3を超えるデータポイントは外れ値と見なされます。しきい値は、データの分布に基づいて調整できます。
偏った分布を持つデータの場合、修正Zスコア法が適用されます。Zスコアは、中央絶対偏差法に基づいて算出されます。
パーセンタイル
パーセンタイルは、データセット内の特定の値の相対的な位置を表す統計的尺度です。パーセンタイルはデータを100等分し、パーセンタイル値はその値以下の値の割合を示します。外れ値はパーセンタイル値に基づいて決定されます。
5パーセンタイルと95パーセンタイルが上限と下限のデフォルト値として設定されています。しきい値は、データの特定の特性に基づいて変更できます。
カスタム範囲
上限と下限に対して任意の値を設定します。外れ値はしきい値に基づいて計算されます。