クラスター分析
クラスター分析は、特定の要因または類似性に基づいて類似のデータポイントをグループ化するために使用される手法です。
Analytics Plus
Cloudは、K平均法、Kモード、Kプロトタイプアルゴリズムを使用してデータポイントをグループ化します。
ユースケース
- 顧客セグメンテーション
人口統計、地域、好みなどの様々な要素に基づいてグループ化できます。グループ化により、企業は販売と顧客維持を向上させるマーケティング活動をカスタマイズし、戦略を立てることができます。 - 在庫管理
効率的な在庫管理により、サプライチェーンの合理化が促進します。クラスター分析により、商品の購入に関連する季節的なトレンドや需要の高いアイテムを特定し、在庫をより適切に管理できるようになります。
留意点
- クラスター分析には少なくとも5つのデータポイントが必要です。
- クラスター分析は、散布マップ、棒グラフ、バブル グラフでサポートされています。
- クラスター分析は、予測、傾向線、異常分析ではサポートされていません。
クラスター分析の適用
以下の手順でクラスター分析を適用します。
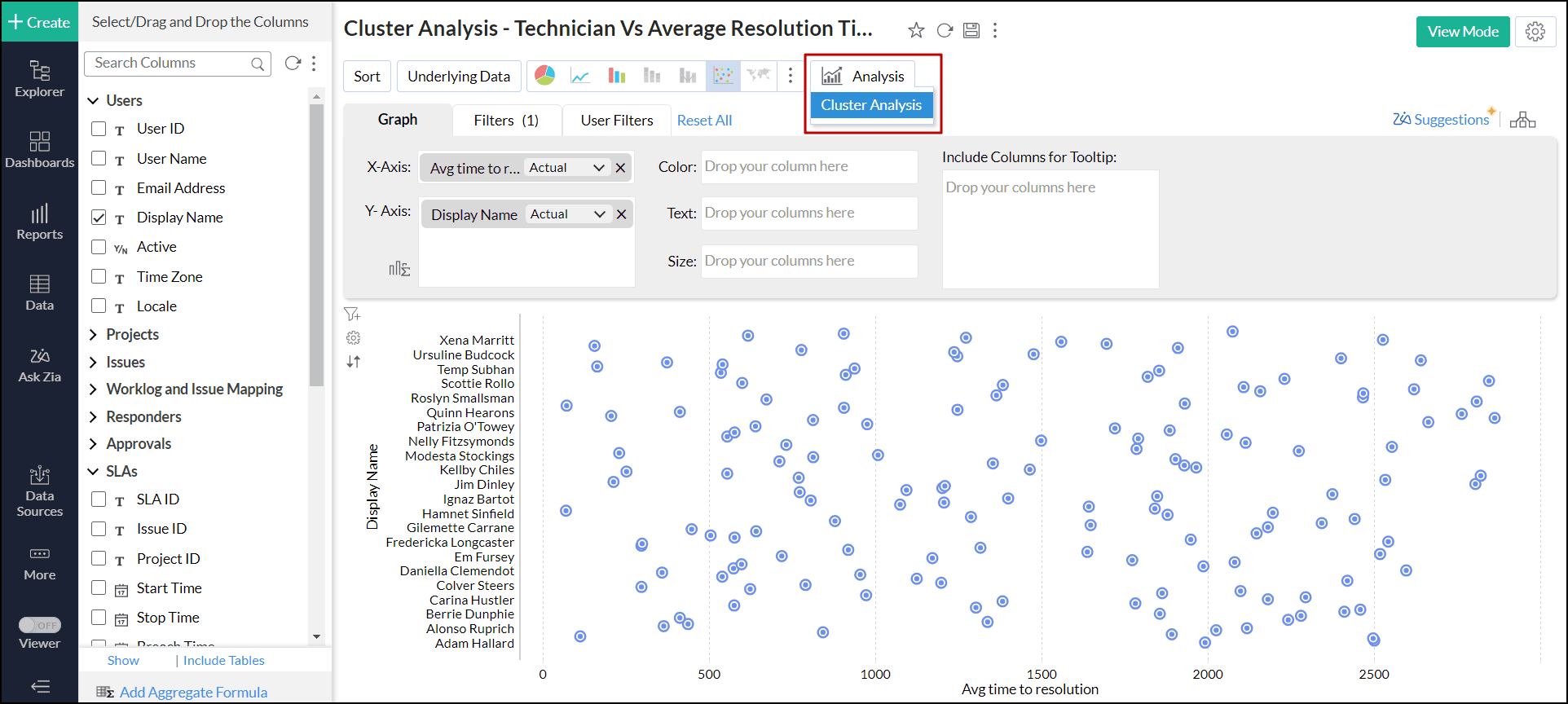
- 対象のレポートを編集モードで開き、ツールバーの分析アイコンから[クラスター分析]を選択します。
![analytics-cluster-analysis-option]()
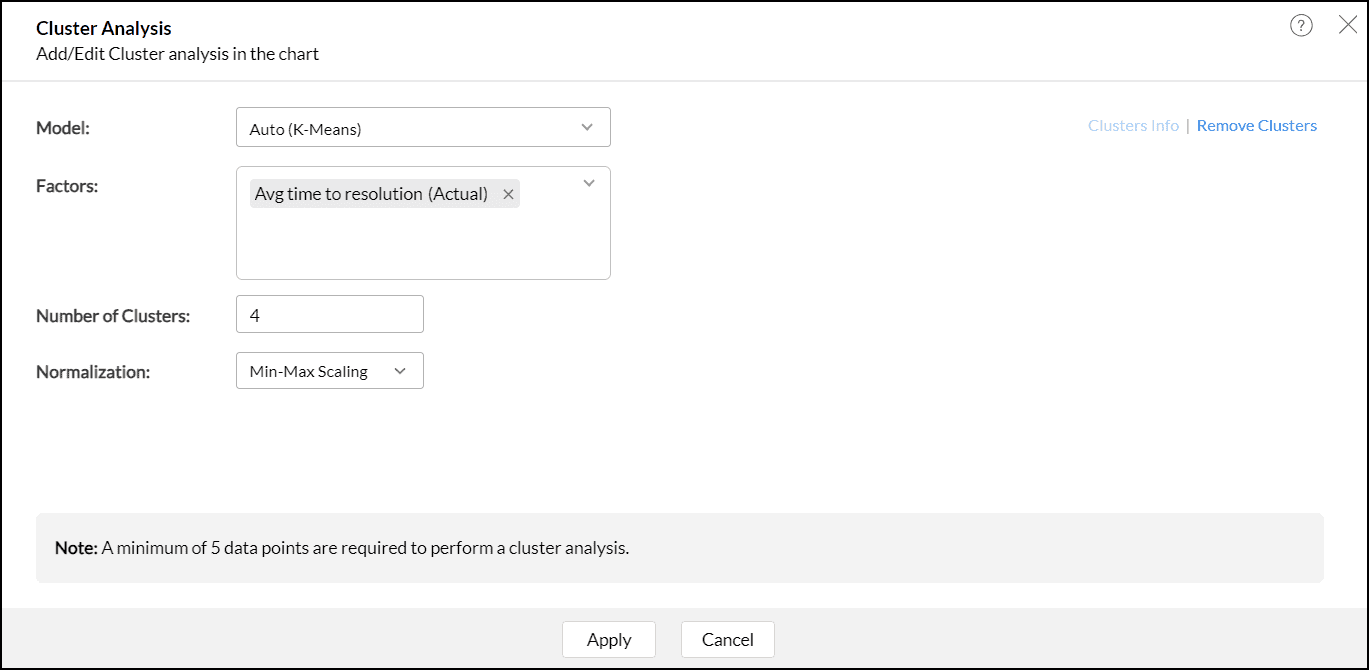
- 表示されたクラスター分析のダイアログで、[クラスターを追加する]をクリックします。
- アルゴリズムモデルは、レポートで使用されるカラムに基づいて自動で選択されます。
- 要因は、データポイントをグループ化する基準となるカラムで、選択したモデルに基づいてリストされます。
- K平均
データで使用可能なすべての数値カラムがリストされます。 - Kモード
カテゴリカラムがリストされます。 - Kプロトタイプ
数値とカテゴリの両方がリストされます。
- K平均
- クラスター数は、データポイントの数に基づいて自動で決定されます。
クラスター分析には、最小2個、最大30個のクラスターを指定できます。クラスターの数は、データポイントの数より1つ少なくする必要があります。![analytics-cluster-analysis-dialog]()
- クラスター分析を適用する前にデータ変換するための正規化方法を選択します。
正規化は、データを共通のスケールに変換するために使用される手法です。- 最大/最小のメモリ
すべてのデータポイントが0から1の範囲で再スケールされます。 - Zスコア
データポイントがデータセットの平均から、どのくらい標準偏差が離れているかを表します。
この変換ではデータを平均0を中心に揃え、データセット全体の標準偏差が1になるように設計されています。この方法では、すべてのデータポイントが-1から1の範囲で再スケールされます。
- 最大/最小のメモリ
- Kプロトタイプモデルの場合、数値およびカテゴリの要因から与える重みを指定します。
重み付け値の範囲は0.2~ 2 です。デフォルトでは、Analytics Plus Cloudは数値要因とカテゴリ要因の両方に等しい重み(1.00)を与えます。重み付け値が0.2に近いほど数値カラムの重み付けが高くなり、値が2に近いほどカテゴリカラムの重み付けが高くなることを示します。 - [適用する]をクリックします。
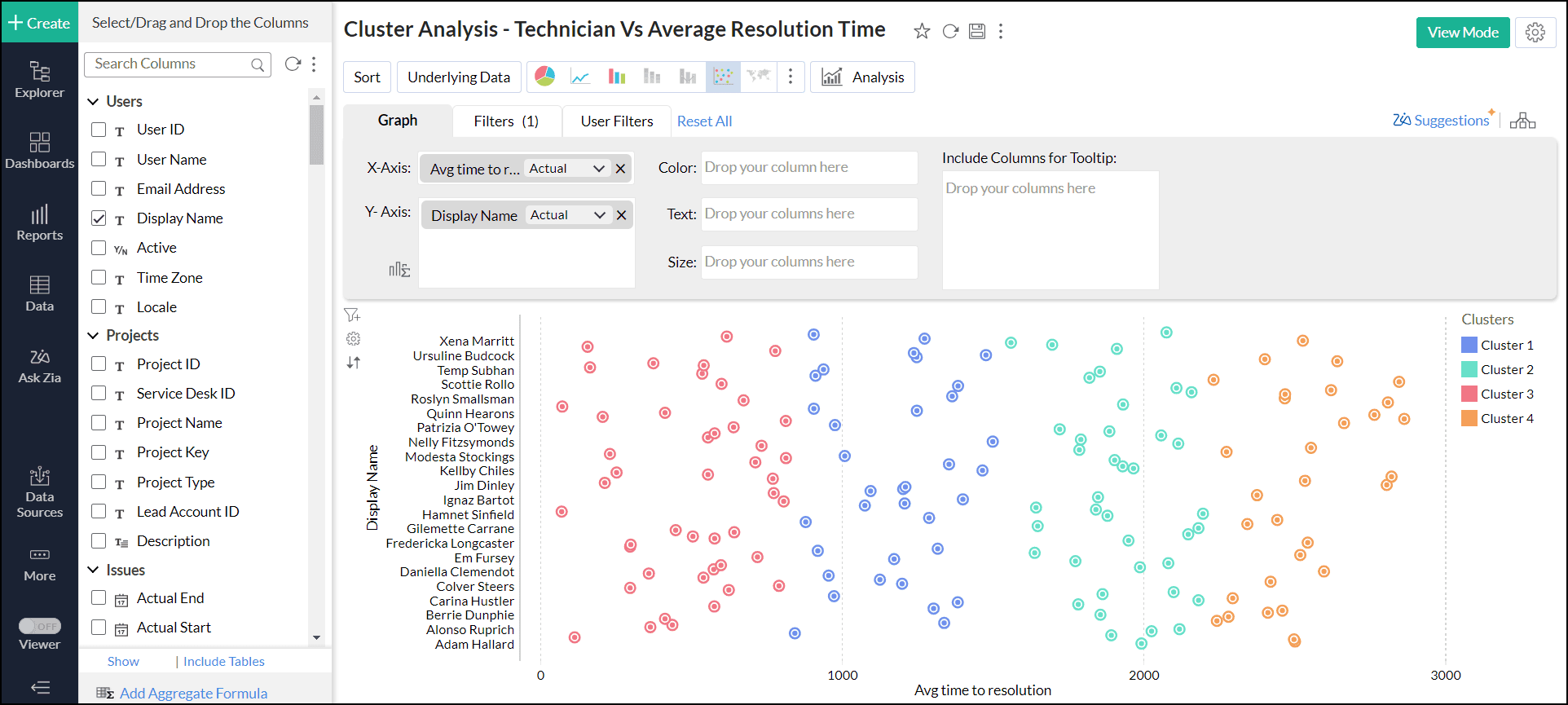
クラスター分析の情報の表示
クラスター分析が適用されると、クラスターの情報オプションが有効になります。
集計
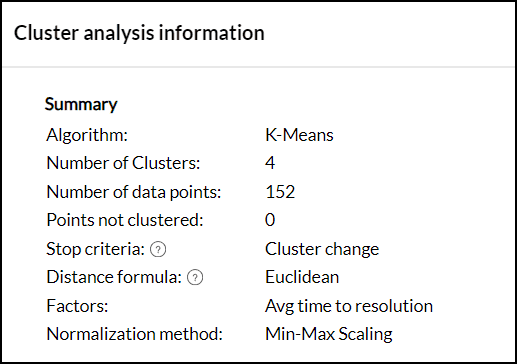
このセクションでは、次の情報を表示します。
- クラスター分析に使用されているアルゴリズム、データポイントの件数、データポイントがクラスター化されるクラスター数などの情報
- 停止条件フィールドには、クラスター分析の処理を停止する条件が表示されます。
- クラスター分析に使用された距離の数式
- ユークリッド距離は、K平均法アルゴリズムで使用される方法です。
- バイナリ非類似度は、Kモードアルゴリズムで使用される方法です。
- クラスター分析に使用される要因 と正規化方法
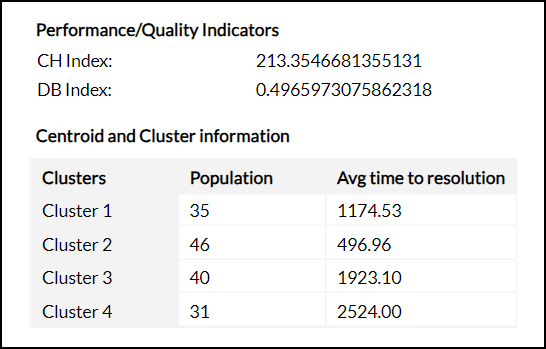
評価/品質指標
- CHインデックス/Calinski-Harabaszインデックス(CHI)
クラスター分析の品質を評価するためのメトリックです。
クラスター間分散とクラスター内分散の比率を計算します。CHI値が高いほど、クラスターが適切にグループ化されていることを示します。 - DBインデックス/Davies-Bouldinインデックス(DBI)
クラスター分析の品質を評価するためのメトリックです。
各クラスターと最も類似したクラスター間の平均類似度と、クラスター間の平均非類似度の比率を考慮して計算されます。
重心とクラスターの情報
各クラスター内のデータポイントの数と、各要因のデータポイントの重心に関する詳細を示します。
分散分析(ANOVA)
ANOVAは、複数のグループの平均値の差を計算するために使用される統計手法です。
ANOVAテストは、仮説検定中に帰無仮説を棄却できるか確認するために使用される統計的有意性検定です。
- 平方和の範囲内
各グループ内の個々のデータポイントがそのグループの平均からどれだけ異なるかを計算します。 - 平方和
異なるグループの平均値が全体の平均値とどれだけ異なるかを計算します。
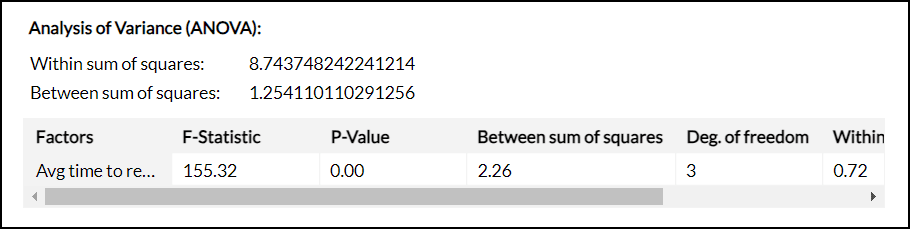
F統計値
F統計は、クラスター間の平均二乗(MSB)とクラスター内の平均二乗(MSW)の比率を計算します。
F統計値が臨界値より大きい場合、データポイントは適切にクラスター化されていることになります。
| 要因 | F補正項 | 平方和 | 自由度(クラスター間) | 平方和の範囲内 | 自由度(クラスター内) |
| クラスター分析に使用されるカラム | MSB/MSW
|
平均値のグループ間の変動 | k-1 k-クラスターの数 |
平均値のグループ内の変動 | N-k
|