
重大インシデント管理の概要

月曜日の朝、サービスデスクではいつも通りに業務が行われています。ところが突然、重要なITサービスが停止してい るというアラートチケットが届き、その後、続々と同じ問題を報告するチケットが殺到します。Webサイトのダウンや POSソフトウェアの不具合ならまだ対応しやすいですが、場合によってはITの問題で株式市場の停止や飛行機の欠航 など、影響が広範囲に及ぶことがあります。ITが要因となりビジネスが深刻な影響を受け、収益や信頼が損なわれるような場合を、重大インシデントと呼びます。
重大インシデントにどう対応するかで、影響の範囲やサービス復旧のスピードに大きな差が生まれます。「時は金なり」 という言葉は、重大インシデント対応においては真実といえます。組織に 重大インシデント管理(MIM:major incident management)プロセスがあれば、重大インシデントに迅速に対応し解決することができます。そのようなプ ロセスがない場合は、まずは緊急対応計画(重大インシデント対応プロセス)を作成する必要があります。
すべての組織が重大インシデントを排除できることが理想ですが、大前提として重大インシデントを完全に防ぐことは 難しいため、わたしたちができることは備えることです。
このガイドでは効果的なMIM(重大インシデント管理)プロセスの設定方法、MIMに影響を与えるよくある間違い、およびMIMプロセスを改善するためのベストプラクティスをご紹介します。
重大インシデントとは?

重大インシデントとは、組織全体あるいは事業の主要部分に影響を与え、かつ大きなインパクトを持ち、緊 急性の高い問題を指します。重大インシデントが発生すると、ほとんどの場合、組織のサービスが利用でき なくなり、結果として事業に打撃を与え、最終的には財務状況にも多大な影響を及ぼします。十分に準備されたサービスデスクで、重大インシデントを評価し、影響を軽減および制御するためのソリューションや回避策を見つけ出すことができます。
重大インシデントの4つのステージ
重大インシデントには主に以下の4つの段階があります:

それぞれ4つの段階において、どのようなプロセスを実装すべきかを見ていきましょう。
重大インシデントプロセス

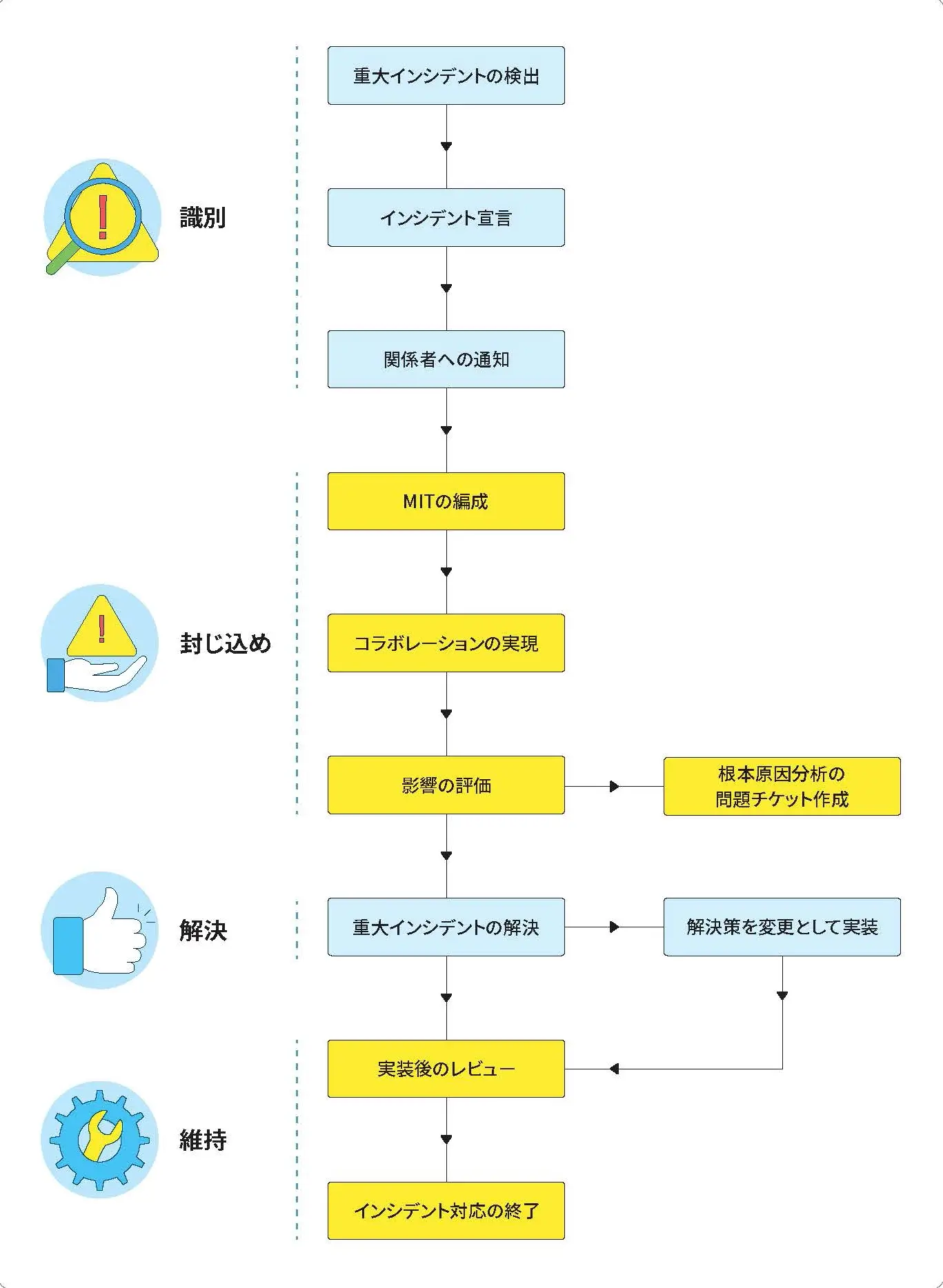
組織にとって重大インシデント管理プロセスは必須であり、ビジネスへの影響を最小限に抑えるのに役立ちます。重大インシデント管理プロセスは主に以下の段階で構成されます:
ステージ1:識別
重大インシデント宣言
最初のステップは、重大インシデントの可能性があるものを特定することで す。組織が脅威を識別できる複数の方法を設定することが重要となります。 技術者が通常とは異なるチケットに遭遇した際にフラグをたてたり、ネットワ ーク監視ツールなどで自動的にネットワークの問題を検出し、サービスデス クに警告するチケットを作成することで重大インシデントを検出することが できます。サービスデスク担当者が重大インシデントを疑った場合に、フラグ をたて、報告するための専用ホットラインを用意する方法もあります。
関係者への通知
重大インシデントが特定されたら、すべての主要関係者に通知する必要があります。重大インシデン トについて通知する必要のある関係者として、以下の4つのグループが挙げられます:
- 技術チーム: 問題を解決するための行動方針の決定を開始するために、直ちに技術チームに情報を提供することが重要です。
- 管理側・経営陣: 上級管理職に重大インシデントを通知することは、担当者が説明責任を果たす上で必要です。重大インシデントを解決するためのすべての手順についても経営陣に通知す る必要があります。
- 主要なステークホルダー: 部門長やサービスレベル管理スタッフにも重大インシデントについて通知し、定期的な状況更新を行う必要があります。
- ユーザー: 重大インシデントによってどのサービスが利用できなくなるか、ユーザーに知らせる必要があります。

ステージ2:封じ込め
重大インシデント対応チームの編成
重大インシデント対応チーム(Major Incident Team:MIT) は、技術者、サービスレベル管理責任者、その他の主要な 関係者で構成されます。時には、重大インシデントに対処す るために高度な技術を持つ外部の専門家を招聘する必要があることもあります。MITは協力して、重大インシデントに 対する解決策を見つけ、運用を通常の状態に戻すために 動いていきます。
会議用ブリッジの設置
会議用ブリッジとは、複数のグループが多拠点から参加できる電話会議を指します。効果的なトラブルシューティングと集中的なコミュニケーションに役立ちます。MITのメンバー間で、明確で迅速なコミュニケーションチャネルとして機能します。
MIT専用の危機対策室の準備
MIT(重大インシデント対応チーム)メンバー専用の危機対策室を用意することで、メンバーが集まり、インシ デントのトラブルシューティングを行いやすくなります。メンバー同士の共同作業が促進され、迅速に解決策を見つけやすくなります。
根本的な問題を特定するための問題チケットの作成
問題チケットを作成することで、重大インシデントの根本原因を発見し理解することができます。原因に対処することで、将来起こりえる類似のインシデントを防げるようになります。

ステージ3:解決
解決策を変更として実装する
重大インシデントの修正を変更として実装することは、解決策の文書化と実装を確実にするための良いプラクティスとなります。 解決策を変更として実装すると、その後、不完全な解決によって他のサービスが中断されるリスクを抑えることができます。

ステージ4:維持
実装後のレビューの実施
インシデントが確実に解決されているかどうかを一定期間監視し評価することが重要です。根本的な問題が未解決のまま残されると、別の重大インシデントにつながる可能性があります。
明確な文書の作成
重大インシデントの解決プロセス全体を文書化することで、組織は将来の類似のインシデントに備えること ができます。過去のインシデントの適切な文書化によって、類似の他の重大インシデントに直面したときに、試験済みの解決策をすぐに実装でき、その影響を軽減することができます。
メトリクスの測定
サービスデスクのパフォーマンスを測定することで、 サービスデスクとMIMプロセスの有効性を判断する ことができます。測定する重要なメトリクスには、平均認識時間(MTTA)、平均解決時間(MTTR)、 重大インシデントの総数、重大インシデントの平均ダウンタイムがあります。
重要インシデント管理を実現する
重要インシデント管理プロセスフローチャート
重大インシデント管理の5つのよくある間違い

MIMプロセスを妨げる可能性がある5つの一般的な間違いは以下になります:
1.手動によるコミュニケーションとエスカレーション
MIMにとって最大の課題はコミュニケーションです。重大インシデントの際には、さまざまな関係者にインシデントの状 態、深刻度、および問題解決のために実行されたトラブルシューティングについて通知する必要があります。これらすべ てを手作業で伝達するのは大変な作業であり、一貫性のないコミュニケーションにつながる可能性があり、事態をさらに悪化させるだけです。しかし、プロセスを自動化することで、主要な関係者はチケットの全ライフサイクルにおいて通 知を受け取り、重大インシデントマネージャーは問題解決に集中することができます。
2.重大インシデントを報告するための非効率なチャネル
毎日、サービスデスクはノートパソコンの問題からサービスリクエストまで、数十もしくは数百のチケットを受け取ります。この大量のチケットの中に、いくつかの潜在的な重大なインシデントがあるかもしれません。重大なインシデントを報告する別のチャネルを設定していない場合には、インシデントの特定が遅れてしまいます。
3.作業の重複
MIT内でのタスクを組織的に委任しないことにより、作業の重複が生じる可能性があります。MITの各メンバーにタスクを割り当て、誰が何を担当しているかをMITに通知することが重要です。
4.不十分な文書化
適切なドキュメントが不足している場合、類似の重大なインシデントが発生するたびにMITは対応策を見つけるのに時 間を取られ、インシデントの解決が遅れ、不必要なダウンタイムが発生してしまいます。
5.根本原因の分析の失敗
MIMは、問題を解決し、可能な限り短時間でサービスを稼働させることを主な目的としているため、近視眼的な視野に陥る可能性があります。根本的な問題を特定する ための問題管理と組み合わせて実施しなければ、重大インシデントの根本原因分析がいつまでも続き、組織は重 大インシデントに対して脆弱な状態が続いてしまいます。
重大インシデント管理の5つのベストプラクティス

MIMプロセスに取り組むためのベストプラクティスを紹介します。
1.重大インシデントを報告するための複数のチャネルを有効にする
重大インシデント対応では、時間が決め手になります。重大インシデントが検出されたら迅速に特定し分類することが 不可欠です。ユーザーがインシデントを報告しやすいよう複数の方法を提供することで、プロセスを迅速かつ容易に進めることができます。メールやWebポータル経由でチケットを作成できるようにしたり、潜在的な重大インシデントを報告するために専用ホットラインを設定する方法もあります。異常を検出するネットワーク監視ソフトウェアを設定すると、インシデントに先手を打って対応するのに便利です。
2.サービスデスクプロセスの自動化
重大インシデントの影響を制御するには、スピードと効率が重要です。サービスデスクのさまざまなプロセスを自動化 すると、技術者が関係者への通知などの反復的なタスクを省略でき、インシデント解決という目的達成を早めやすくなります。通知システムの自動化と、重大インシデントワークフローの設定は解決時間を短縮し、確実なMIM プロセスを実行しやすくなります。
3.迅速かつ適切なコミュニケーションを心がける
経営陣と重要な関係者に、すべての重大インシデントを知らせることが重要です。経営陣に情報を提供し続けることで、重大インシデントの解決に必要な承認や許可を得やすくなります。迅速なコミュニケーションによって、重大インシデントの担当者全員が同じ認識を共有し、スムーズで効果的な協力体制が可能になります。またエンドユーザーにダウンタイムの可能性について知らせ、あらかじめ対策ができるように情報を提供します。
4.明確な文書化の実施
明確な文書化システムがあれば、重大インシデント管理者は、インシデント解決におけるすべての作業、その影響、影響を受けたサービス、その他インシデントに関する重要な情報を記録できます。この文書はROIを含むMIMプロセスのメリットを経営陣に示すために重要です。明確なドキュメントは将来、同様の重大インシデントが発生した場合にも役立ちます。
5.ITOMソフトウェアとの連携機能を利用する
ITOM(IT運用管理)ソフトウェアと連携することで、IT部門は重大インシデントに対処しやすくなります。重大インシデントの特定は、大量のチケットが送られてくることから、インシデントが進行中であることがわかります。一方で、ITOM連携を活用した積極的なMIMプロセスでは、ネットワークとサービスを監視するシステムがあり、重大インシデントになる可能性のある異常を、自動的にフラグを付けて検出できます。
重大インシデント管理のメトリクスとKPI
MIMに関して追跡すべき重要なメトリクスとKPIは以下になります。
| KPI | 計算式 | 備考 |
|---|---|---|
| 平均解決時間(MTTR) | 重大インシデントが報告されてから解決されるまでの平均時間 | この数字はサービスデスクが重大インシデントをどれだけ早く解決できるかを示します。MTTRが短いほど、MITが効果的かつ効率的であることを示します。 |
| 平均認識時間(MTTA) | 重大インシデントに対応する平均時間 | MTTAが短いということは、サービスデスクが重大インシデントに迅速に対応していることを示しています。 |
| 平均故障間隔(MTBF) | 障害が1度発生してから、次に発生するまでの平均稼働時間です。総稼働時間を総故障回数で割って計算します | この指標はITインフラの性能を示します。MTBFが高いことは、ITインフラが良好に機能していることを意味します。 |
| 平均検出時間(MTTD) | 重大インシデントまたは異常を検出するまでの平均時間 | 重大インシデントがどれだけ早く識別されるかを測定する数値です。MTTDが小さければ、サービスデスクが主要なインシデントを迅速に検出していることを意味します。 |
| 重大インシデントの増加または減少割合 | 最初の月と比較し、その後に続く月の問題の増加割合 | この指標はインシデントの発生傾向を特定するのに役立ちます。 |
インシデント管理の用語集

変更
直接的または間接的にサービスに影響を及ぼす可能性のあるものの追加、変更、または削除。
変更管理
中断や衝突を最小限に抑えながら変更を完了するプロセス。
エスカレーション
機能的または階層的な必要性に基づいてチケットの所有権を移転する行為。
イベント
サービスまたは資産の管理にとって意味がある発生事象。
階層的エスカレーション
所有権を垂直に上位層のサービスデスク技術者または関連する権限に移転する行為。
影響(インパクト)
インシデントの重大度を測る指標。
インシデント
ITサービスの計画外の中断、またはITサービスの品質の低下。サービスにまだ影響を与えていない設定項目の障害も、インシデントである(例:ミラーリングされたディスクのうち1台の障害)。
インシデント管理
できるだけ迅速に通常のサービス運用に復旧し、ビジネスへの影響を最小化するため、すべてのインシデントのライフサイクルを管理するプロセス。
インシデントの優先順位付け
インシデントに優先順位を割り当て、重大インシデントを定義すること。
重大インシデント
影響度と緊急度が高く、インシデント管理とは別のプロセスが必要なインシデント。
重大インシデントマネージャー
MITとMIMプロセスの実装を担当する人物。
障害
サービスまたは資産が合意されたSLAに従って機能しない発生事象。
平均認識時間(MTTA)
サービスデスクがインシデントを認識するまでの平均時間を測る指標。
平均検出時間(MTTD)
サービスまたは設定項目に対する潜在的脅威を検出するまでの平均時間を測る指標。
平均故障間隔(MTBF)
サービスまたは資産が故障する頻度を測る指標。
平均解決時間(MTTR)
障害発生後にサービスを復旧させるまでの平均時間を測る指標。
通常のサービス運用
サービスレベル契約(SLA)に準拠するサービス運用。
問題
一つまたは複数のインシデントの原因または潜在的原因。
RACIマトリクス
部門横断的なプロジェクトやプロセスにおける役割と責任を定義する。
サービスデスク
サービス提供者と組織のユーザーとの間のコミュニケーションポイント。
サービスデスクマネージャー
サービスデスクの日常活動を監視し、そのパフォーマンスに責任を持つ人。
サービスレベル目標(SLO)
サービスプロバイダーの目標を定義し、そのパフォーマンスを測る手段。
SLA
サービスプロバイダーと顧客の間の、提供されるサービスレベルとその納期に関する合意。
緊急度
インシデントをどれだけ早く解決する必要があるかを示す指標。
FAQ
インシデント管理とは、ITサービスの中断に対応し、サービスレベルアグリーメント(SLA)で定められた時間内にサービスを復旧させるためのプロセスです。その範囲は、エンドユーザーが問題を報告することから始まり、サービスデスク担当者がその問題を解決するまでを含みます。
一方で、重要インシデント管理(MIM)は、組織全体に重大な影響を与えるインシデント、サービスの広範囲な停止や複数部署に及ぶ障害など、通常のインシデント対応ではカバーしきれない重大な事象に特化した管理プロセスです。
MIMの範囲は、複数の情報源から報告された重大インシデントを特定するところから始まり、サービスデスクによる事後レビューで終わります。このレビューは、重大インシデントの対応方法をより深く理解し、MIMプロセスを改善するために欠かせないステップです。