データ予測
Analytics plus Cloudでは、予測アルゴリズムに基づき過去のデータを詳細に分析し、将来のデータのトレンドを効果的に予測できます。
QA
- 予測とは何ですか?
- 予測を設定するための前提条件は何ですか?
- 予測を設定する方法
- 複数のY軸を横断して予測を設定できますか?
- 色付きのグラフで予測を設定できますか?
- Analytics plusCloudでは予測はどのように機能しますか?
- 共有ユーザーの場合、予測ポイントの表示が異なっているのはなぜですか?
- 予測データポイントでは元データオプションは使用できますか?
- データに適用された予測モデル情報を表示できますか?
エラーメッセージに対するトラブルシューティングのヒント
- データが完全に無視されるため、予測は無効になります。
- パターンを識別するのに十分なデータがないため、予測は無効になっています。
- 空の値が40%以上あるため、予測は無効になっています。
- 5つ以上のデータポイントが必要なため、カラムを予測できません。
QA
1.予測とは何ですか?
Analytics plusCloudの予測機能は、過去のデータを詳細に分析して将来のトレンドを予測するアルゴリズムに基づいています。
2.予測を設定するための前提条件は何ですか?
予測を設定するための前提条件は次のとおりです。
- 正確な予測を行うには、少なくとも7つのデータポイントが必要です。
- 対象のグラフは次の通りです。
折れ線グラフ、棒グラフ、積み上げ棒グラフ、散布マップ、面グラフ、積み上げ面グラフ、Webグラフ、複合グラフ(バブルグラフなし) - グラフのX軸には日付カラムを含める必要があります。
- Y軸には少なくとも1つのメトリックカラムが設定されている必要があります。
- 過去のデータポイントの少なくとも60%は、nullであってはいけません。
- 数値カラムはグラフ内のフィルターとして使用できません。フィルターされたデータに基づく予測では不正確な結果がもたらされる可能性があるためです。
- Analytics plusCloudは、トレンドライン、What-If分析、異常検出の予測をサポートします。
3.予測を設定する方法
グラフで予測の設定手順
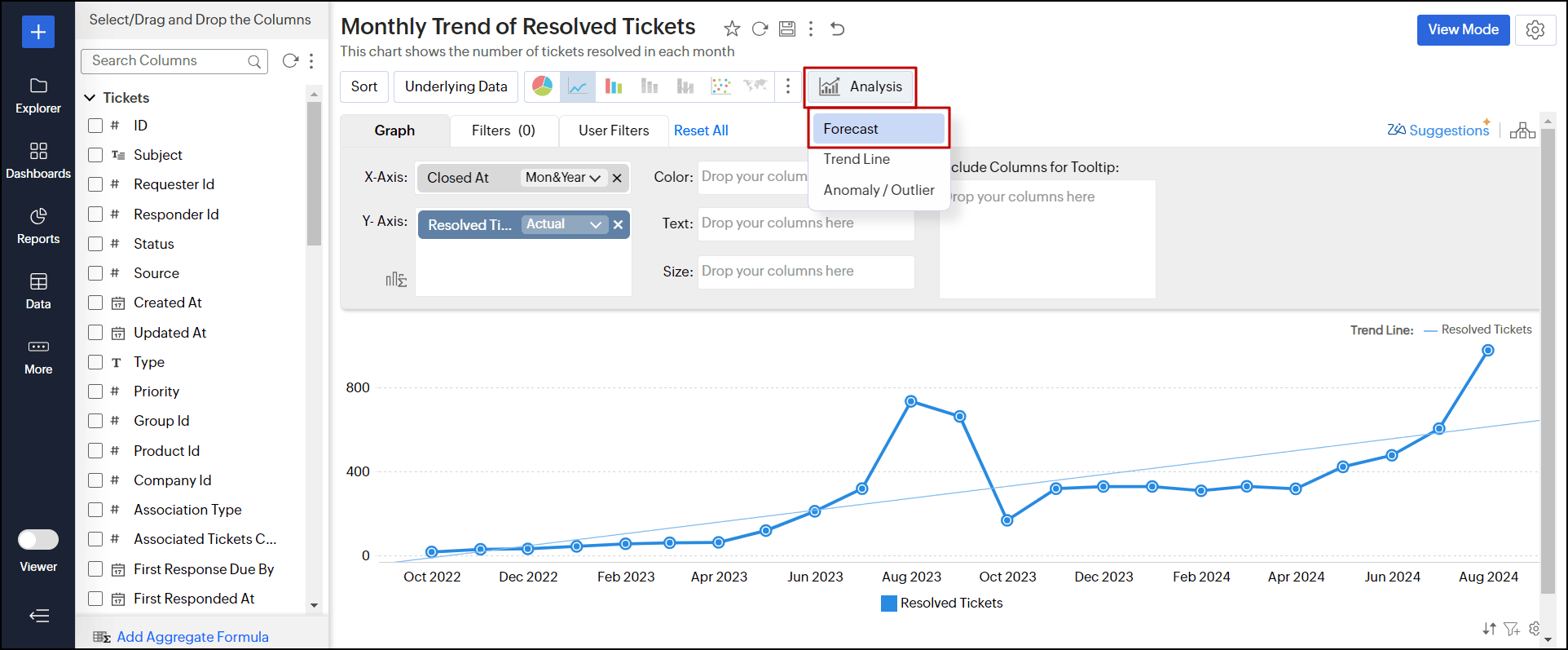
- 設定対象のレポートを開き、[設計を編集する]をクリックします
- [分析]から、[予測]オプションを選択します。
![analytics-forcast-option]()
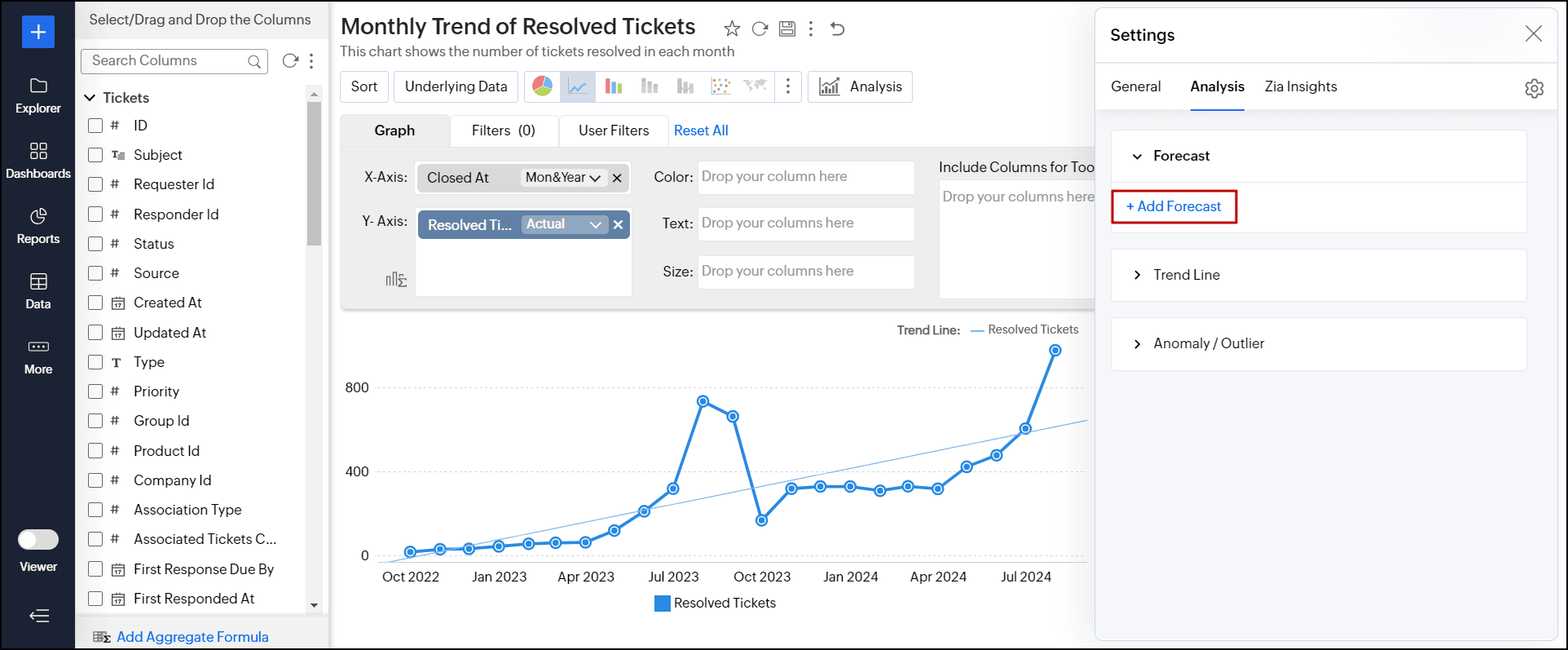
また、レポート画面右上の「設定」アイコンから[分析]タブをクリックし、[予測]→[予測を追加する]からも設定できます。
![analytics-forcasting-settings-dialog-add-forecast]()
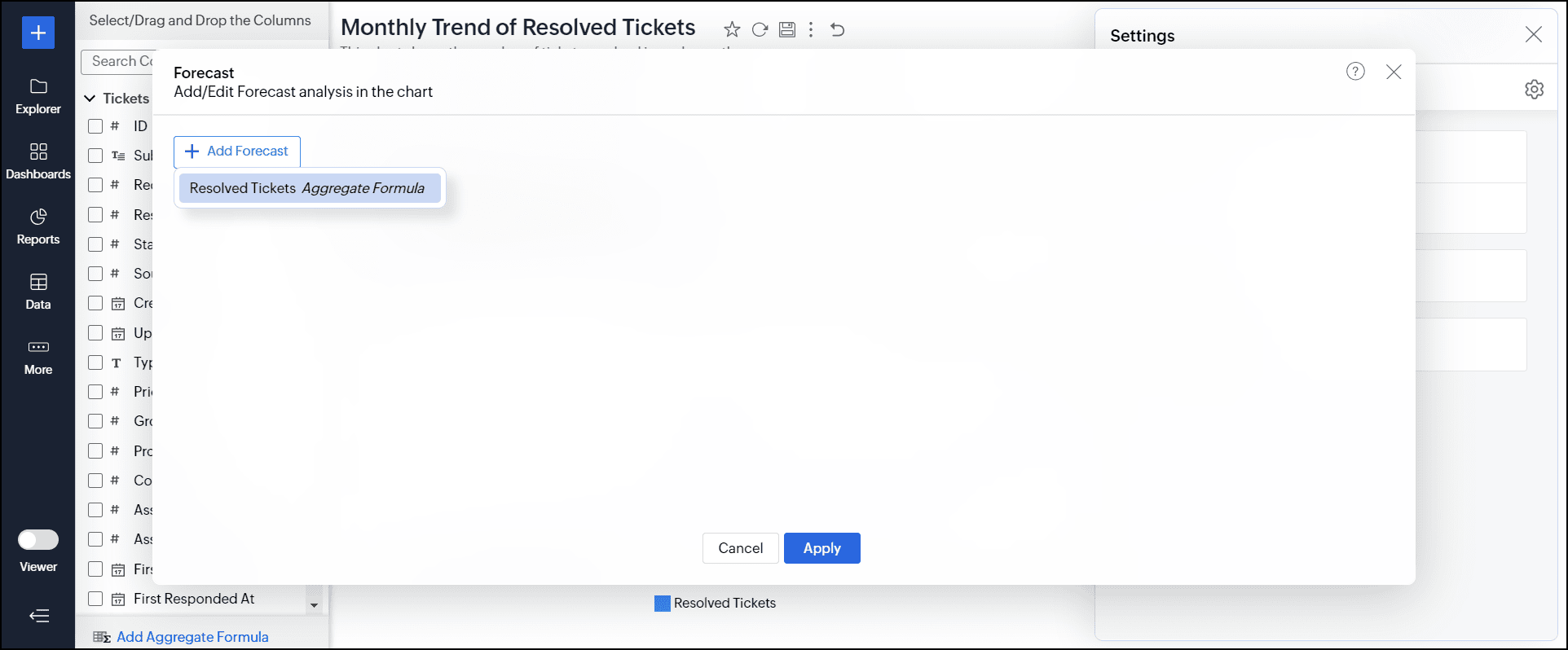
- [予測を追加する]をクリックし、値を予測するカラムを選択します。
![analytics-forcasting-dialog-choose-column]()
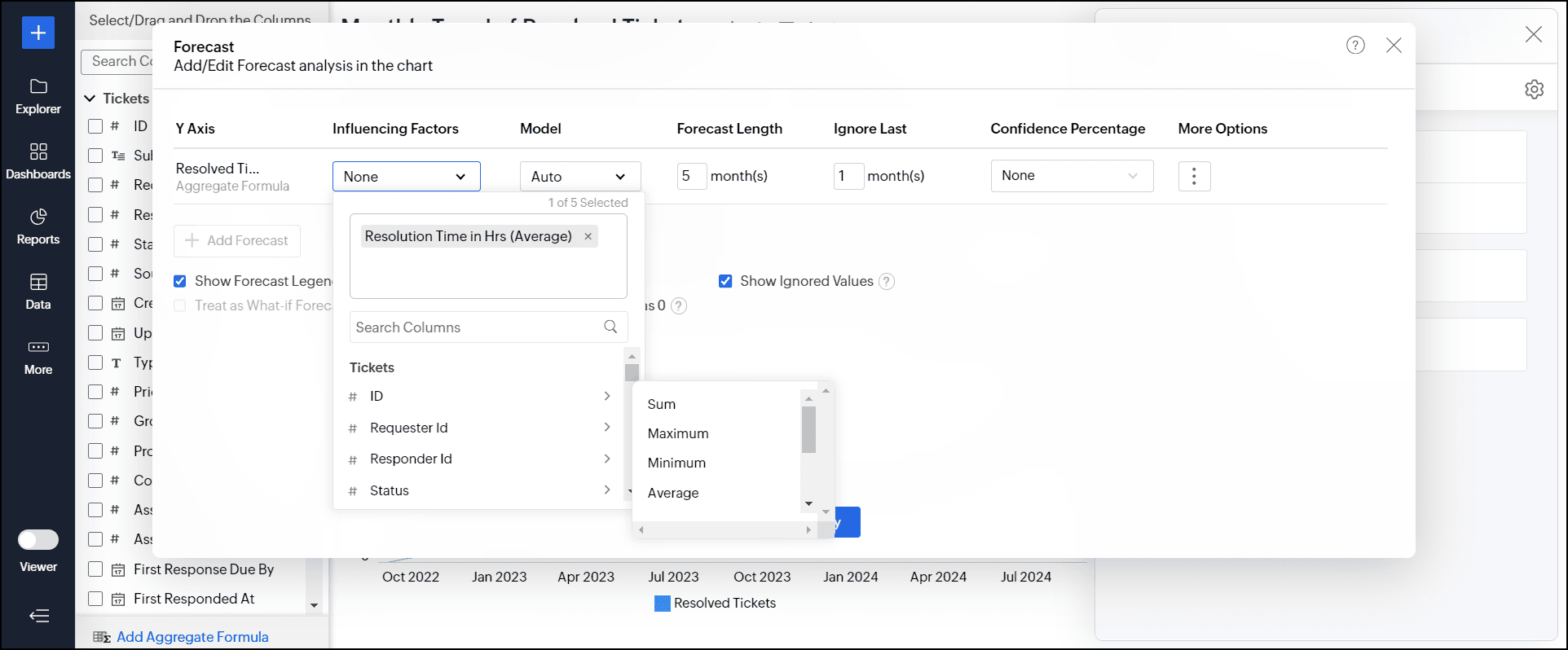
- [影響の高い要素]のドロップダウンから予測の従属要因(カラム)を選択します。
予測対象のメトリックに影響を及ぼす要因を考慮することで、予測の精度を高めるのに役立ちます。例として、技術担当者の可用性や個々の技術担当者の平均解決時間などの影響要因を含めると、より正確な予測を実現できます。
予測データには最大 5つの影響要因を追加できます。![analytics-forcasting-dialog-choose-influencing-factor]()
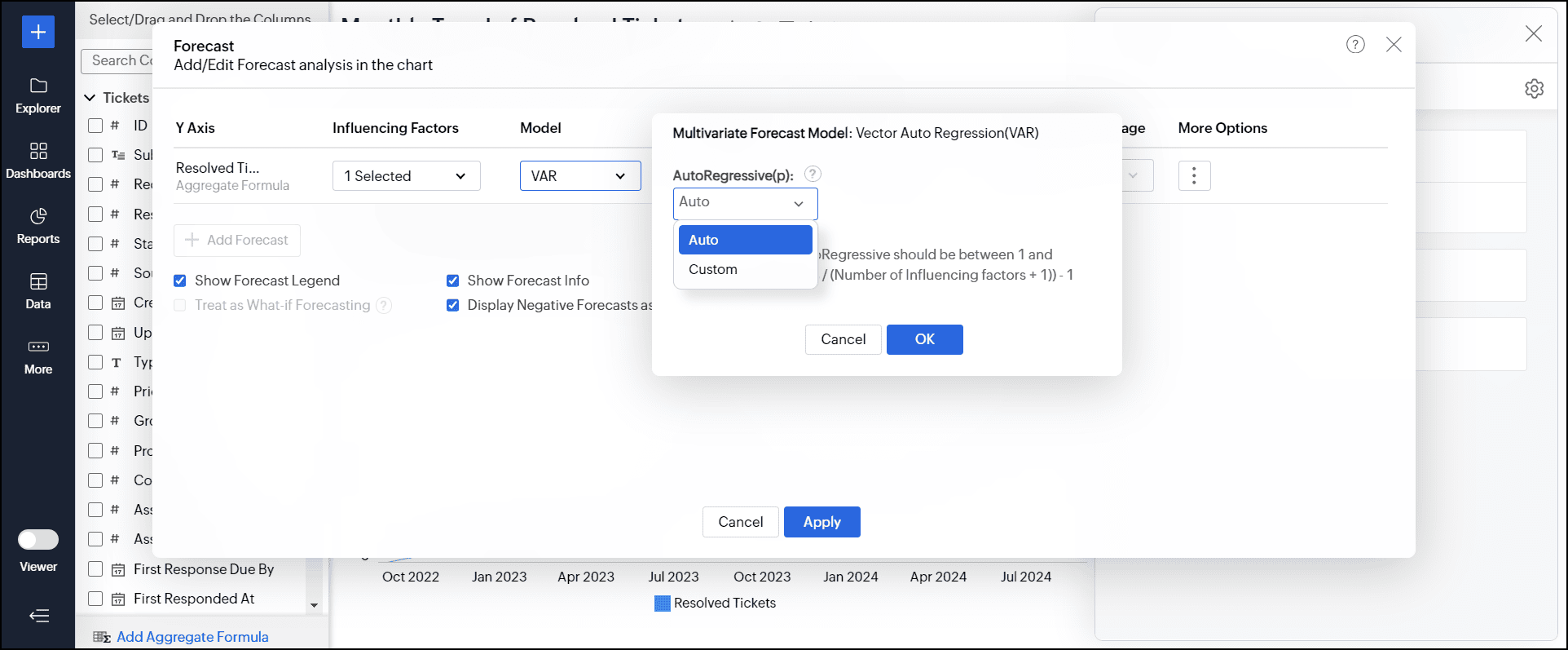
- データの特性に基づいて最適な予測モデルが自動的に選択されます。
予測に影響する要因を選択すると、ベクトル自己回帰モデルがデフォルトで適用されますが、モデルを選択して分析のパラメーターを指定することもできます。
詳細については、予測モデルのドキュメントを参照してください。![analytics-forcasting-dialog-choose-model]()
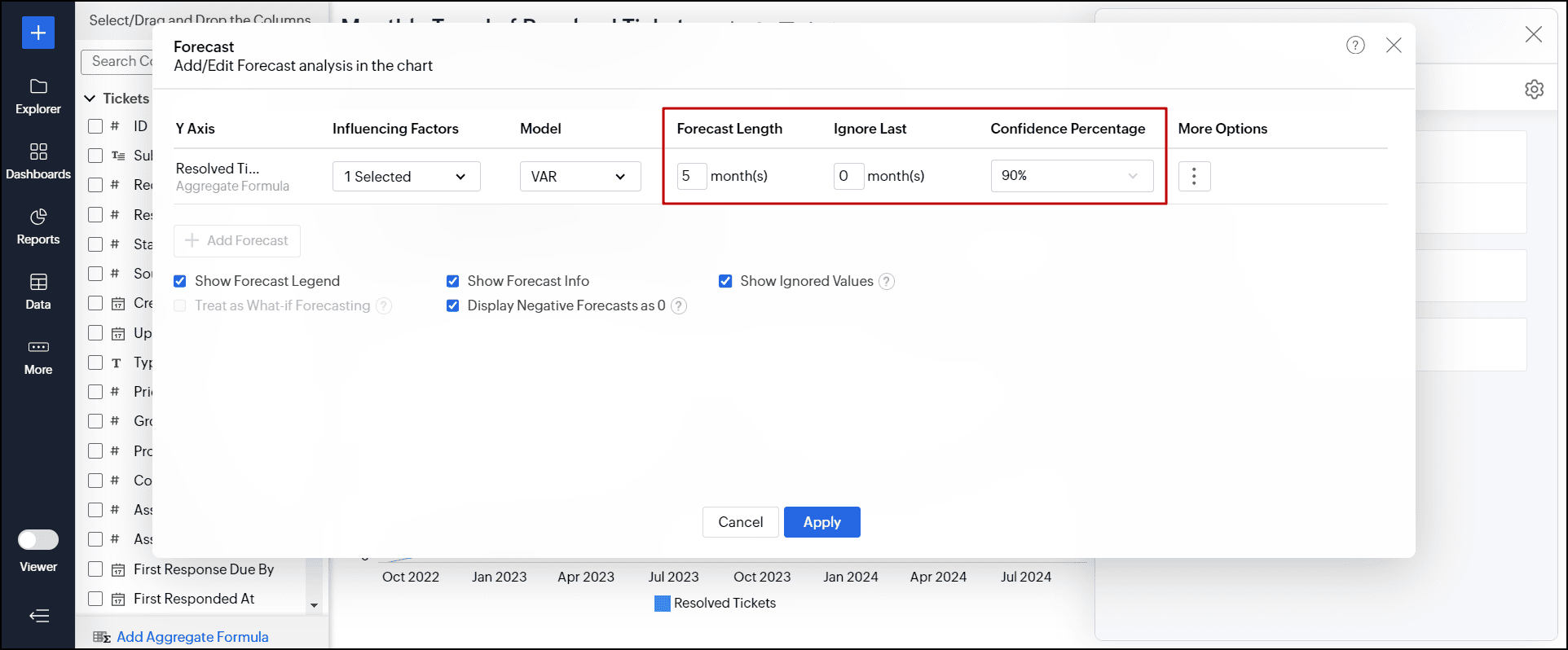
- 「予測の長さ」フィールドで、予測に必要なデータ系列の数を指定します。
- 「最後の値を無視する」フィールドに、データを予測するときに無視するデータ系列の数を指定します。
これは、前期または現期のデータが不完全である可能性があるケースを除外し、選択したモデルが正しい値を予測するのに役立ちます。 - 「信頼区間の割合」ドロップダウンから、データポイントが発生する可能性のある信頼区間を選択します。
このオプションは折れ線グラフにのみ適用されます。![analytics-forcasting-dialog-choose-forecast-length]()
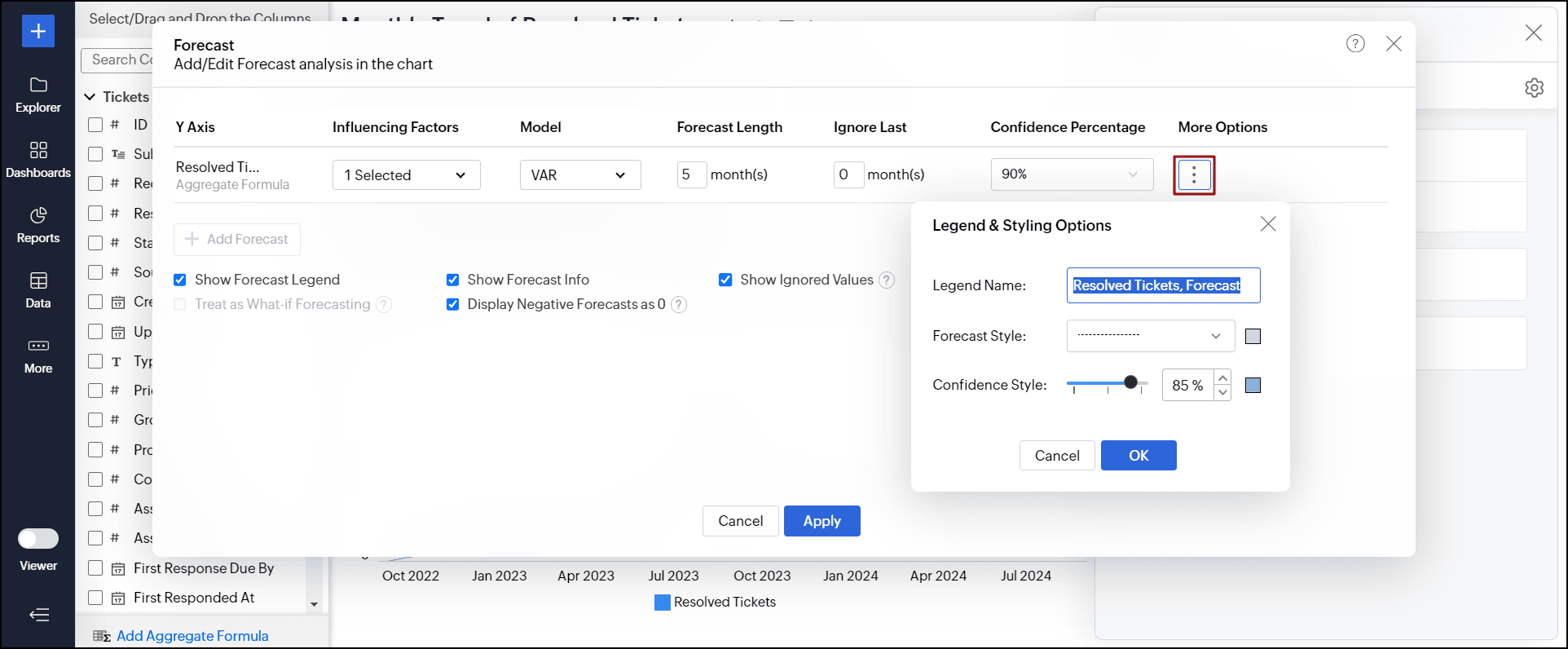
- 凡例とスタイルのオプションをカスタマイズするには、「その他の操作」アイコンをクリックします。
- 凡例名
フィールドに予測系列のタイトルを入力します。 - 予測のスタイル
データを予測線に使用する色と線の形式を選択します。
「信頼区間の割合」を選択している場合は、「信頼区間のスタイル」オプションを使用して必要なスタイルを選択できます。
![analytics-forcasting-dialog-more-options]()
- 凡例名
- 複数のメトリックカラム(複数のY軸)に予測を適用するには、[予測を追加する]オプションをクリックします。
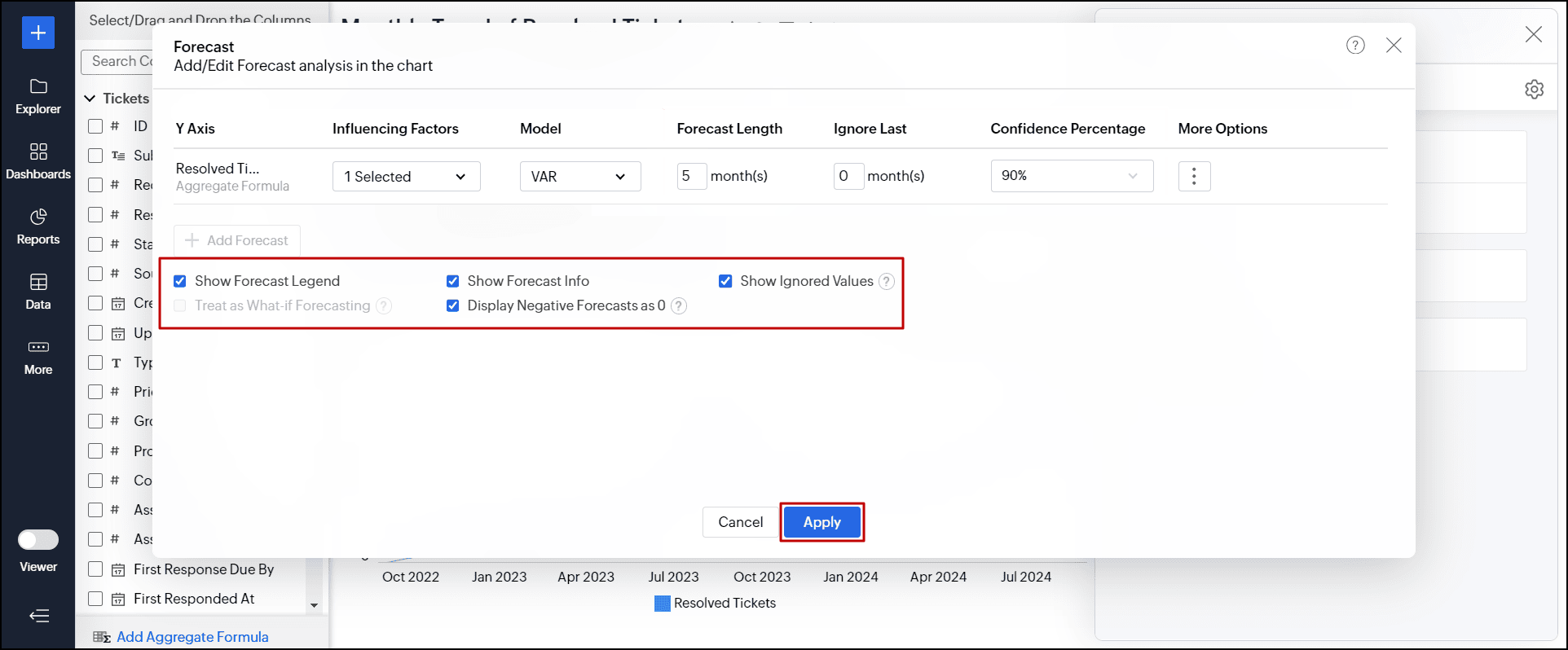
- 必要に応じて次のオプションを選択します。
- 予測の凡例を表示する
予測値と実際の値を区別するための凡例を表示します。 - 予報情報を表示する
予測とパフォーマンスメトリックに使用されるモデルに関する詳細情報を表示します。
デフォルトで有効になっており、表示モードと編集モードから予測情報にアクセスできます。 - 無視された値を表示する
予測プロセスで使用されていない値を表示します。 - What-if分析の予測値として設定する
変数とユーザーフィルターを通じて入力を選択的に変更することで、将来の結果を予測します。 - 負の予測値を0として表示する
すべての負の予測値を0に変換します。
- 予測の凡例を表示する
- [適用する]をクリックします。
例として、以下の折れ線グラフは90%の信頼区間の割合で予測されています。
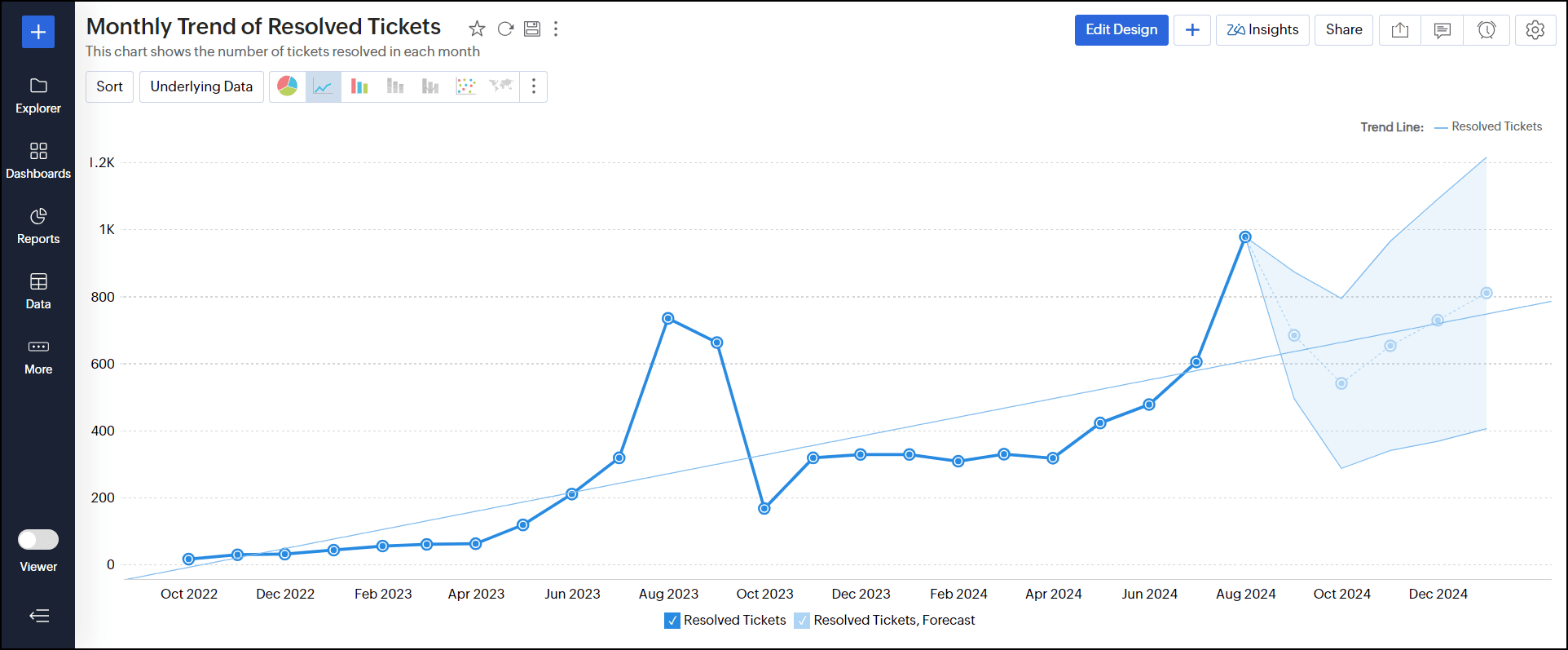
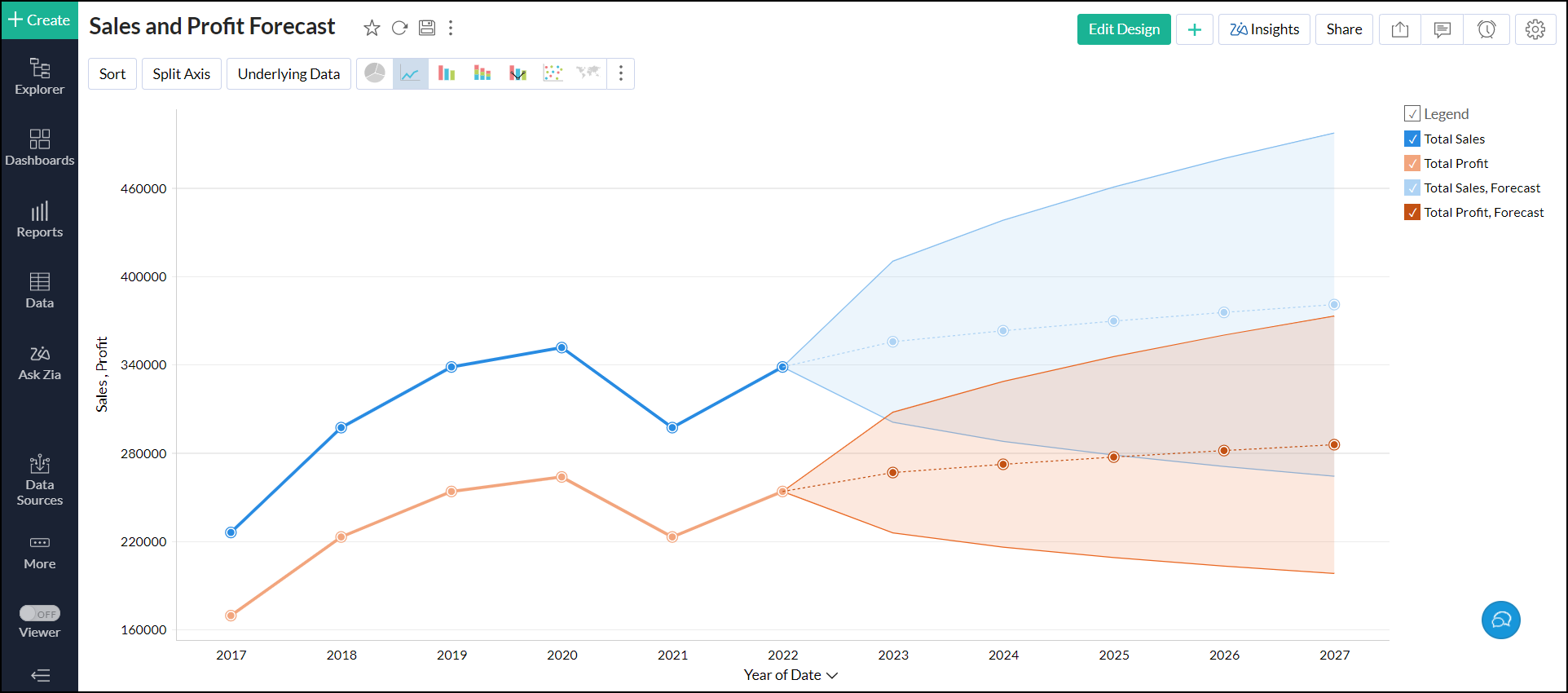
4.複数のY軸を横断して予測を設定できますか?
はい。グラフ内の複数のY軸を横断して予測を設定できます。
5.色付きのグラフで予測を設定できますか?
はい。「色」にカラムがあるグラフに対して予測を設定できます。
Y軸に基づいて予測を適用し、すべての色系列を予測します。

6.Analytics plusCloudでは予測はどのように機能しますか?
Analytics plusCloudは、過去のデータに基づいて将来のデータポイントを予測する予測エンジンを提供します。
予測エンジンでは、予測するユニット数、過去のデータで無視するデータポイントの数、予測データポイントに適用する書式設定など、カスタマイズが可能です。
Analytics plusCloudでの予測の仕組みは以下の通りです。
- 予測エンジンにより過去のデータポイントを分析し、自己相関技術を使用して周期性を識別します。
- データの季節性、トレンド、ランダム性が計算され、反復処理を使用して微調整されます。
- 予測エンジンは線形回帰、対数回帰、指数回帰を実行し、データ系列を線形、対数、または指数として分類します。
- 予測の精度は、ハインドキャスティングを使用して検証されます。
予測結果を使用して過去のデータポイントを推定し、過去の実際のデータで検証する一種のバックテストです。 - 検証が完了すると、予測エンジンは予測されたデータポイントを表示します。
7.共有ユーザーの場合、予測ポイントの表示が異なっているのはなぜですか?
異なるフィルター条件でレポートをユーザーと共有した場合、過去のデータポイントの数はユーザーごとに異なります。
その場合は予測ポイントも異なります。
8.予測データポイントでは元データオプションは使用できますか?
いいえ。Analytics plusCloudは、予測データポイントの基礎となるデータを生成しません。
そのため予測データポイントでは、元データの表示とドリルダウンのオプションは使用できません。
9.データに適用された予測モデル情報を表示できますか?
はい。Analytics plusCloudでは、グラフに適用された予測モデル情報を表示できます。
使用されたモデルの詳細と、予測モデルの精度を評価するための統計データが提供されます。これらは予測が適用された後に使用可能になります。情報は予測される各メトリックに固有のものです。
表示モードと編集モードの両方で予測モデル情報にアクセスできます。
表示モードで、予測データポイントのいずれかをクリックします。
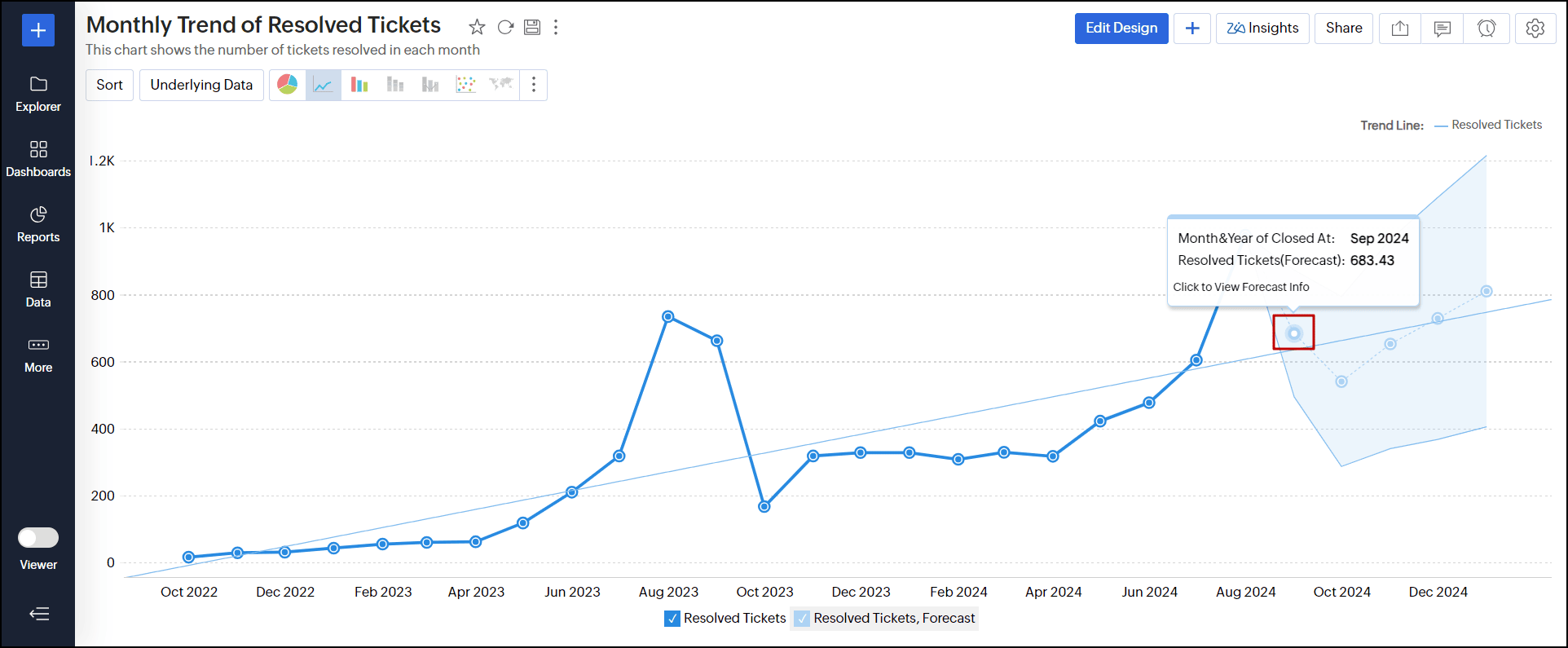
編集モードで、[設定]アイコン→[分析]タブをクリックし、予測セクションから[編集]をクリックします。
表示されるダイアログで、必要な予測の上にカーソルをあてたときに表示される予測情報アイコンをクリックします。
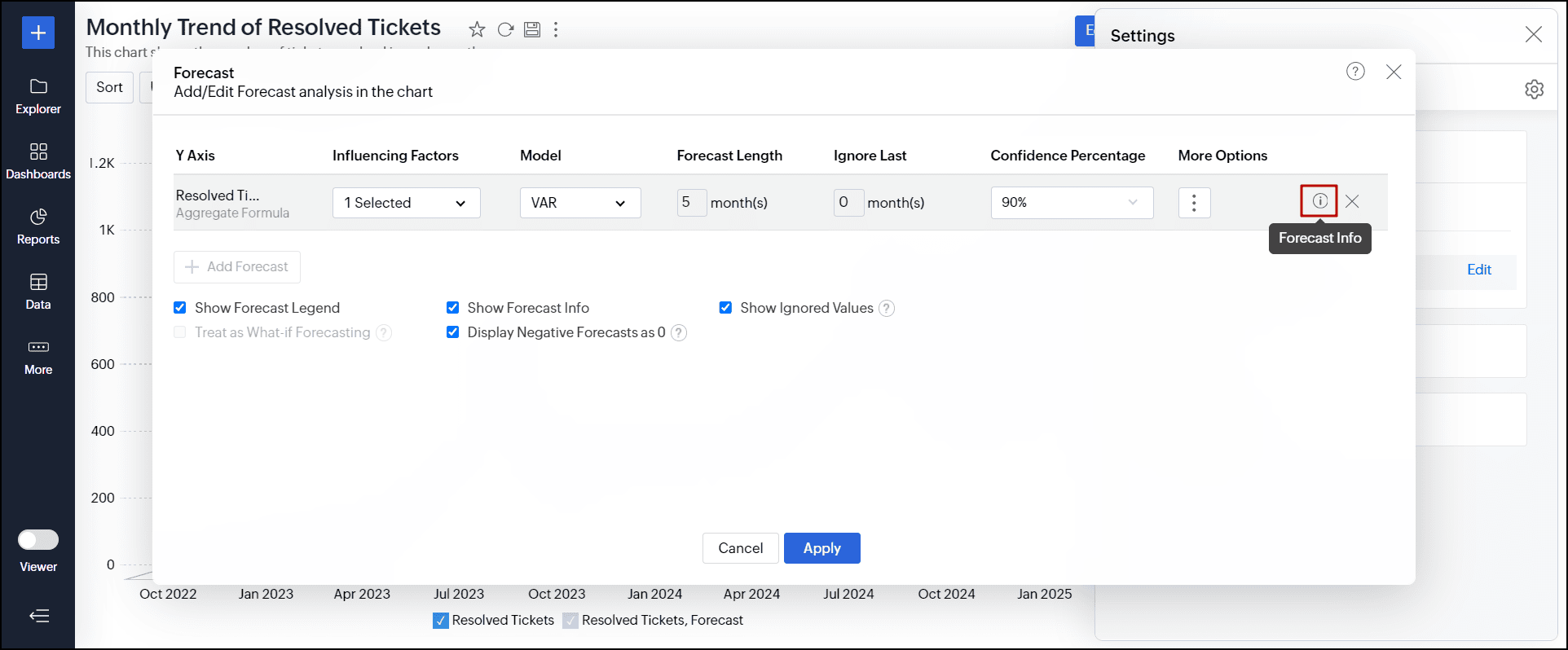
予測モデルのダイアログが次の情報とともに表示されます。
一般情報
このセクションには次の情報が表示されます。
- トレーニング期間
データポイントの予測に使用される履歴データの範囲を表示します。 - 予測期間
データが予測される期間を表示します。
モデル情報
このセクションには、グラフに適用された予測モデルの種類が表示されます。
- 予測モデル
予測に使用される予測モデルを表示します。
Analytics plusCloudは、次の5つの予測モデルをサポートしています。
ARIMA、STL、ETS、回帰、ベクトル自己回帰 - サブモデル
グラフに適用されたサブモデルの名前を表示します。 - 頻度
時系列の頻度を示します。 - データコンポーネント
指定されたデータにトレンドと季節性が存在するか表示します。
予測モデルの要素
このセクションでは、分析に使用される予測モデルのサブメソッドとパラメーターまたは係数値が表示されます。
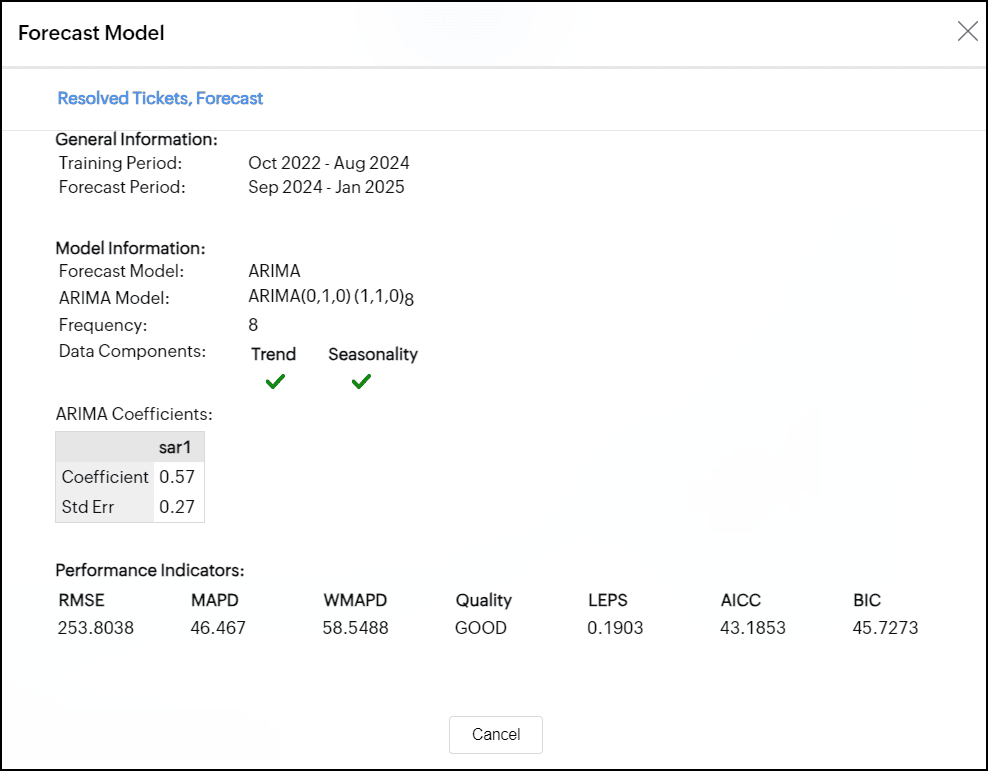
ARIMAモデル
ARIMAモデルは、季節的トレンドと非季節的トレンドの両方を組み込んで過去のデータを分析することで時系列値を予測します。
非季節性コンポーネントは、一貫したパターンを欠く全体的なトレンドと短期的な変動を考慮し、季節性コンポーネントは、一定の間隔で繰り返されるパターンを識別します。
ARIMAモデルは、次の3つのパラメーターによって特徴付けられます。
- AR(自己回帰)
時系列の過去の値を使用して将来の値を予測します。
将来の値を予測するために使用される過去の値の数であり、pとして表されます。たとえばp=2の場合、モデルは最新の2つの値を使用して予測を行います。 - 和分(d)
時系列を定常化するのに役立ちます。
特性として時間の経過とともに変化しません。トレンドや季節パターンを除去してデータが一貫した動作をするようにデータを調整する必要がある回数であるdとして表されます。 - MA(移動平均)
データポイントと以前の予測からのエラーとの関係を調べます。
過去の値に依存するARとは異なり、MAは過去の予測誤差を使用して予測を行います。qとして示され、予測を行うために移動平均(MA)部分で考慮する過去のエラーの数です。
ARIMA値(p, d, q)(p, d, q)mでは、最初の順序付けられた3つ組(p, d, q) は非季節性コンポーネントを表し、2番目の順序付けられた3つ組(p, d, q)m は季節性コンポーネントを表します。
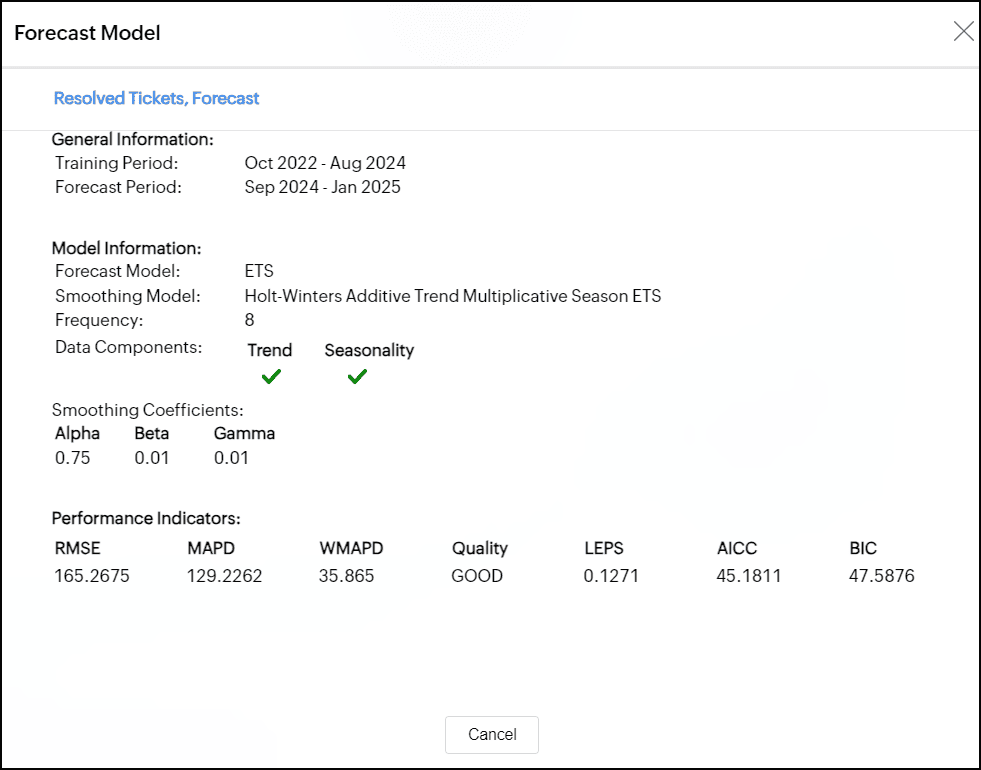
指数平滑法
指数平滑法は過去の観測値の平均を取り、最近のデータに重点を置き、将来の値を予測する予測方法です。
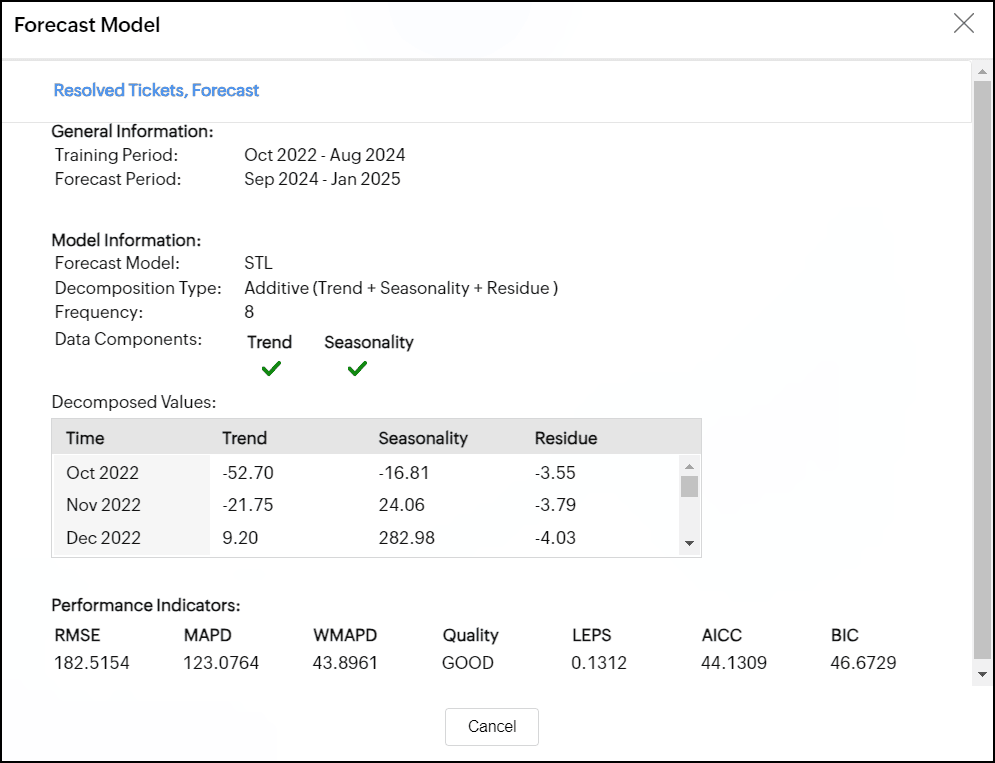
STL
STLモデルでは、データはトレンド、季節性、残差の3つのコンポーネントに分割されます。
モデル情報ダイアログには、パラメーターを平滑化するために使用される分解方法と分解値に関する詳細が表示されます。
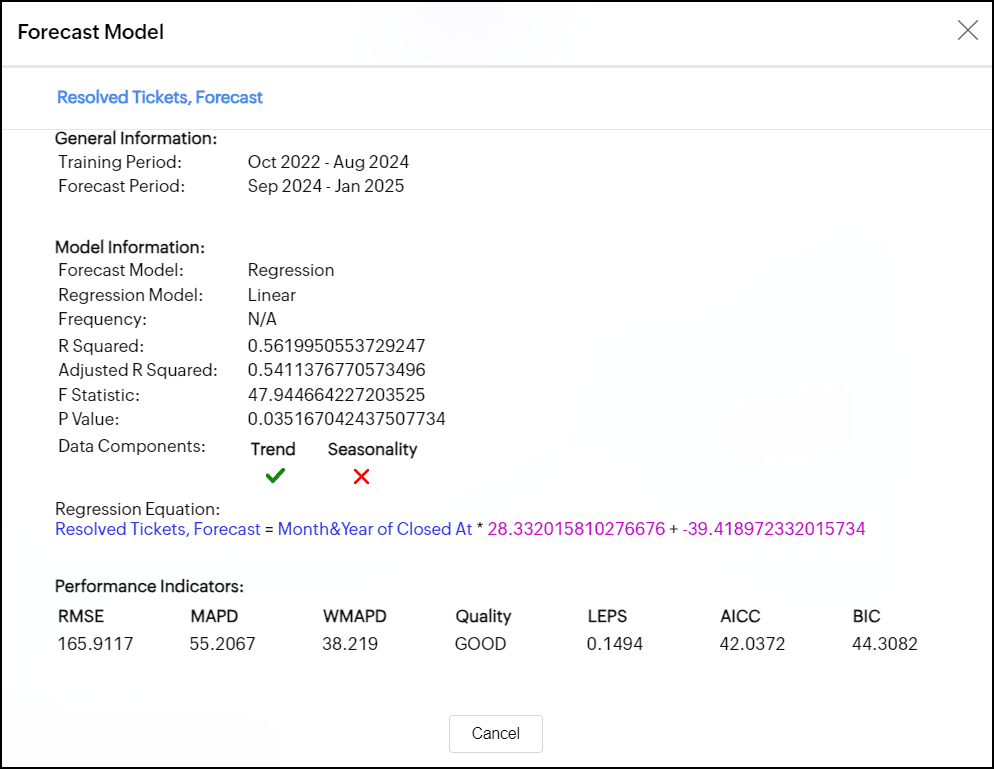
回帰
回帰は、従属変数と1つ以上の独立変数の関係を理解し、モデル化するのに役立つ統計手法です。予測情報ダイアログには、回帰モデルとそのパフォーマンスを評価するために使用される統計手法が表示されます。回帰モデルの種類には、線形、対数、指数、べき乗、多項式などがあります。
以下は、回帰モデルのパフォーマンスを評価するために使用される統計手法です。
- R二乗
独立変数によって説明できる従属変数の変動の割合を示すことによって、モデルがデータにどの程度適合しているかを測定します。
結果の変化の何パーセントがモデル内の要因によって説明されるかを示します。 - 調整R二乗
過剰適合を防ぐためにR二乗が調整されます。
調整R二乗が最も高いモデルが、不必要な複雑さがなく適合性が高いことを示しているため、推奨されます。 - F統計
独立変数が集合的に従属変数に統計的に有意な影響を及ぼすかどうかをチェックし、モデルの全体的な重要性を評価します。 - P値
モデル内の個々の独立変数の重要性が評価され、独立変数と従属変数の関係が統計的に意味があるかどうかを判断するのに役立ちます。
ベクトル自己回帰
複数の時系列が相互に影響を与える場合は、ベクトル自己回帰(VAR)モデルが使用されます。各系列の予測は、その系列の過去の値と他の系列の過去の値に依存します。このモデルは、予測に影響要因が選択された場合にのみ適用できます。
予測情報ダイアログには、過去の観測データがいくつ使用されているかが表示されます。VAR(p)モデルでは、pはモデルが予測を行うために過去の値を調べる期間の数を示します。
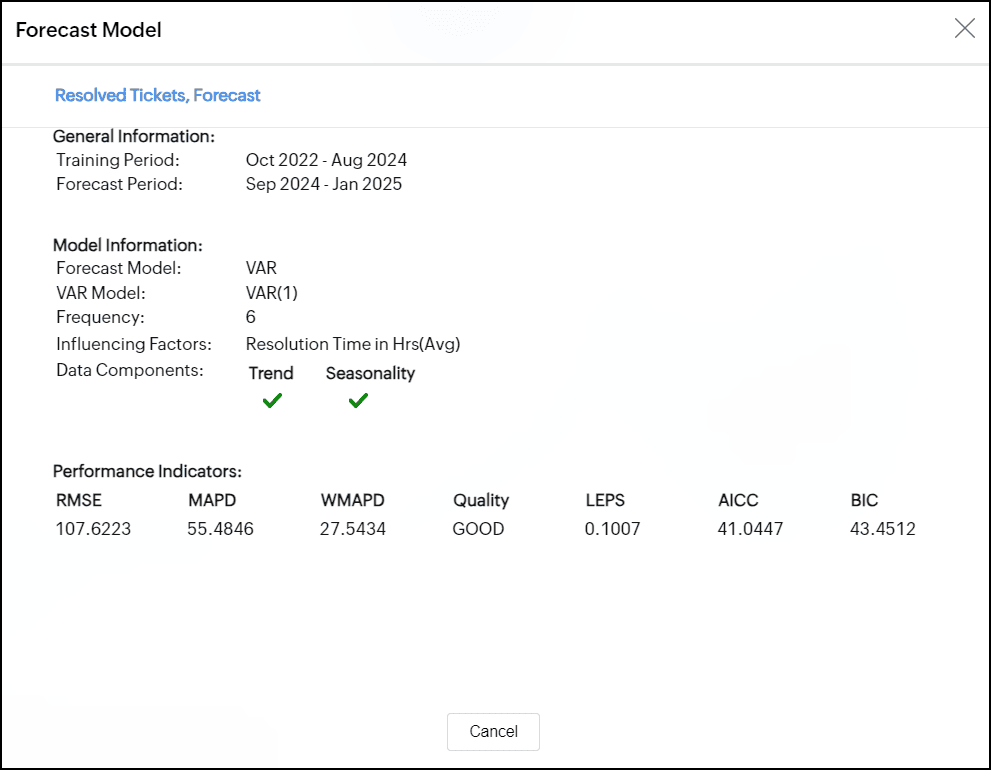
パフォーマンス指標
- 二乗平均平方根誤差(RMSE)
RMSEは、実際の値と予測値の平均差を計算します。 - 平均絶対パーセンテージ偏差(MAPE)
MAPEは、実際の値と予測値の平均絶対パーセンテージ差を計算します。 - 加重平均絶対パーセンテージ差(WMAPD)
WMAPDは、実際の値と予測値の間の絶対パーセンテージ偏差の平均を計算し、各偏差を指定された基準に従って重み付けします。 - 確率空間における線形誤差(LEPS)
LEPSは、予測累積分布値と観測値の平均絶対差を計算します。予測モデルの品質は LEPS に基づいて与えられます。 - 品質
予測モデルの品質は、LEPS値に基づいて決定されます。- LEPSが80%を超える場合、予測モデルの精度は良好であるとみなされます。
- LEPSが30%~80%の場合、モデルの精度は許容可能とみなされます。
- LEPSが30%未満の場合、精度は不良と分類されます。
- ベイズ情報量規準(BIC)
BICは統計におけるモデル選択に使用される別の方法です。
エラーメッセージに対するトラブルシューティングのヒント
- データが完全に無視されるため、予測は無効になります。
このエラーは、[最後の値を無視する]設定で過去のデータポイントをすべて無視する設定が有効になっている場合に発生します。
エラーを解決するには設定を無効にしてください。 - パターンを識別するのに十分なデータがないため、予測は無効になっています。
このエラーは、予測エンジンに予測データポイントを生成するのに十分なデータが生成されない場合に発生します。 - 空の値が40%以上あるため、予測は無効になっています。
このエラーは、指定されたデータポイントにnull値が多く含まれている場合に発生します。null値はデータの予測を不正確にする可能性があるため、予測エンジンは、指定されたデータ内のnull値が40%を超える場合、プロセスを破棄します。 - 5つ以上のデータポイントが必要なため、カラムを予測できません。
このエラーは、予測に考慮されるデータポイントが5ポイント未満の場合に発生します。正確な予測を行うには、グラフに5つ以上のデータポイントが含まれている必要があります。