しきい値だけの障害検知はもう古い?「アノマリ検知」とは?
アノマリ(Anomaly)は日本語で「異常」を意味します。 アノマリ検知は異常検知とも呼ばれます。平常値のパフォーマンス値の範囲から外れた挙動を示した場合を「異常」として扱います。
しきい値での監視との違いは?
ネットワークインフラ監視においてよく利用されるものとして「しきい値」があります。 しきい値とは、ネットワーク通信量やCPU使用率などのパフォーマンス値があらかじめ定義した値を超えた場合に障害と判断する監視方法です。 しきい値を使用した監視は、CPU使用率の突然の急上昇やサーバーの停止など、突発的に発生する問題には非常に効果的な監視方法と言えます。しかし、比較的長期間にわたって徐々に変化するパフォーマンス値などの問題を、いち早く検出することが困難です。
アノマリは、現在のデータを過去のデータと比較して適切な値の範囲であるかを判断します。あらかじめ定義されていない範囲の値であっても、過去データから判断していち早く障害状態の予兆を検知できます。
しきい値だけに頼った障害検知では見逃しがちだった小さな変化を、「アノマリ検知」を実施することで発見できるようになります。
アノマリを用いた一歩先の監視を実現するツール
ManageEngineのアプリケーションパフォーマンス監視ツール(APMツール)である「Applications Manager」は、アノマリ検知技術を用いたアプリケーション監視を実現するソフトウェアです。
Applications Managerでは、以下の2種類の方法で異常を検知します。
ベースライン
特定の週のデータ(固定値)または前週などのデータ(移動値)をベースラインに設定してベースラインを中心とした範囲の値と最新のパフォーマンス値を比較します。 たとえば、基準週として8月の第1週を選択すると、毎週月曜日のデータが8月1日の月曜日の値と比較されます。
カスタム式
ユーザー定義の変数を基準値とすることも可能です。例えば、現在の最後の1時間の平均値が6時間の移動平均値の2倍を超える場合に、異常を検出するなどのルールを作成できます。
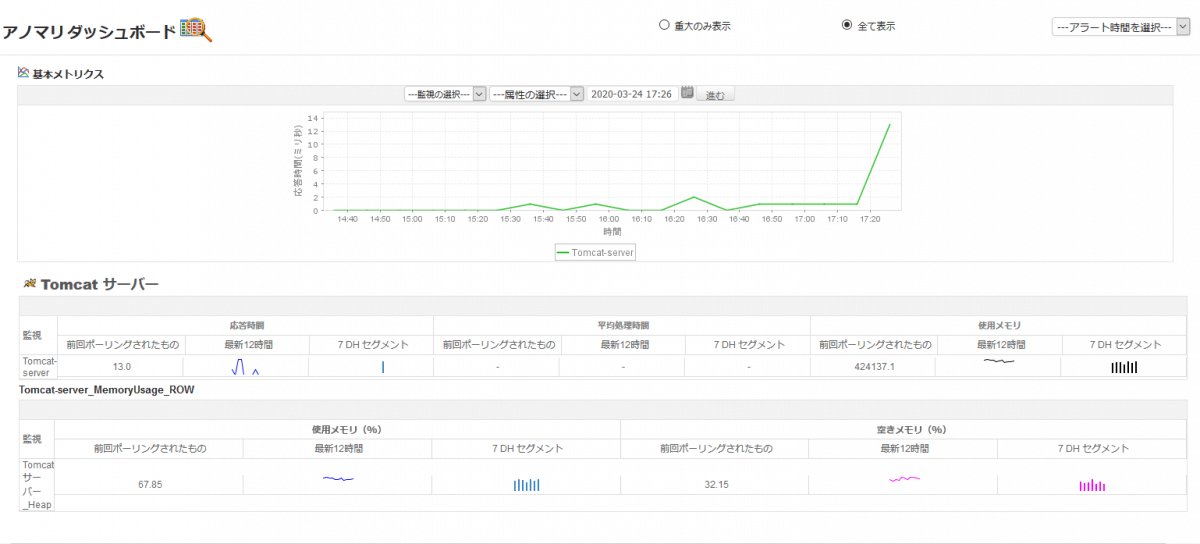 [アノマリ検知-アノマリダッシュボード]
[アノマリ検知-アノマリダッシュボード]
異常を検知した場合はアラートを発生させ管理者にお知らせします。メールやトラップでの通知の他、アラートの発生と同時にコンポーネントの起動・停止・再起動などの自動アクションも設定可能です。これにより、繰り返し発生する問題に費やす時間と労力を削減することが可能です。
Applications Managerで取得したデータは、レポートとして出力して利用することが可能です。傾向分析レポートを使用すると、さまざまな属性の履歴データ、ヒートチャート、および統計レポートを取得して、パフォーマンスの傾向を効率的に分析できます。また、機械学習(マシンラーニング)技術を使ってDockerコンテナの成長と利用率のトレンドを予測できます。利用状況を事前に把握することで、障害の発生を未然に防ぐことが可能です。
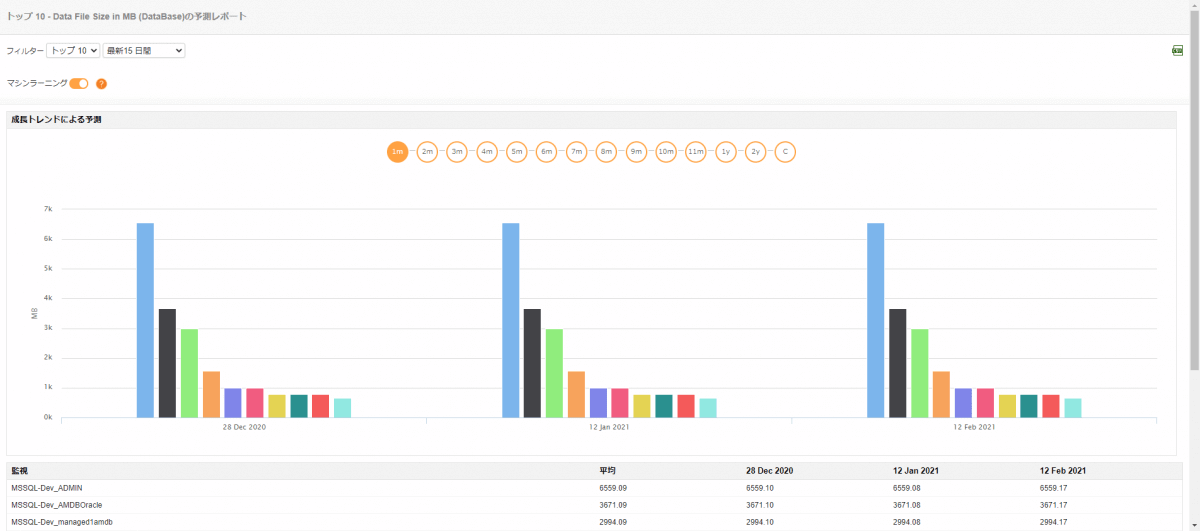 機械学習技術を用いた予測レポート
機械学習技術を用いた予測レポート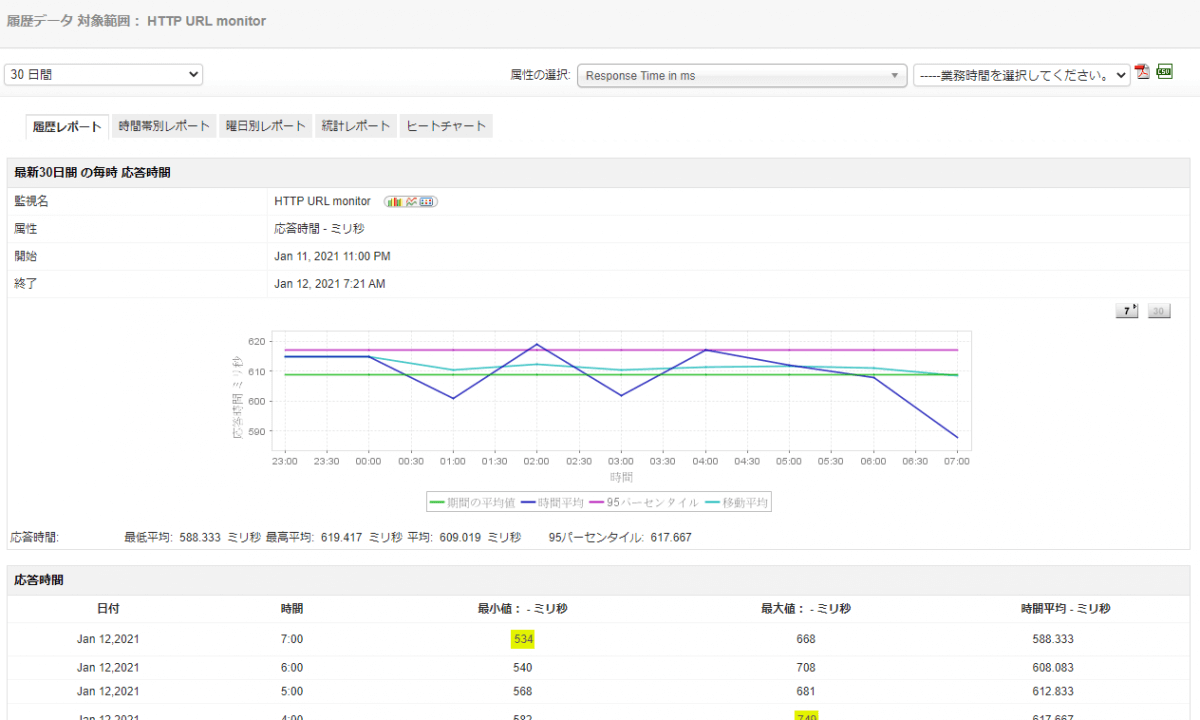 今すぐ活用できる統計分析レポート
今すぐ活用できる統計分析レポートアノマリ検知の詳細情報
- アノマリ検知 ユーザーガイド
アノマリ検知機能のご利用方法やソフトウェア上での操作方法を紹介しています。 - スタートアップガイド
製品の導入手順から設定方法までの詳細ガイドです。
