リソース監視の必要性とは
リソース監視は、システムの障害を未然に防ぎ、安定して稼働させるために非常に重要です。サーバーのリソース状態を把握できていないと、パフォーマンスの低下や高負荷状態といったような障害の兆候を見逃してしまい、やがてはサーバーダウン・システム障害に繋がります。
リソース監視を正しく行えば、障害の兆候を未然に察知し問題が発生する前に修正できるほか、万が一システム障害が発生してしまった場合にも、その原因の特定が容易になり迅速な対応が期待できます。
Linuxサーバーでリソース監視を始めるには
Linuxサーバーでのリソース監視は、コマンドを使用して実現できます。代表的なコマンドと使用方法、その見方を解説します。
CPU使用率
CPU使用率を確認するには、「top」コマンドを使用します。実行方法と応答の例は以下の通りです。
top - 14:19:30 up 1:37, 1 user, load average: 0.02, 0.06, 0.05
Tasks: 324 total, 1 running, 322 sleeping, 0 stopped, 1 zombie
%Cpu(s): 0.0 us, 6.2 sy, 0.0 ni, 93.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 9031500 total, 5496960 free, 2245560 used, 1288980 buff/cache
KiB Swap: 7995388 total, 7995388 free, 0 used. 6475060 avail Mem
(略)
※コマンドを終了するにはqを入力します。
CPU関連のリソース監視の場合は、まず以下の項目を監視することをおすすめいたします。
- us
CPU使用率のうち、「ユーザーモード」でのCPU使用の割合です。 - sy
CPU使用率のうち、「カーネルモード」でのCPU使用の割合です。
CPUには「ユーザーモード」と「カーネルモード」の二種類があります。ほとんどの場合、アプリケーションはユーザーモードで、OSの基本動作はカーネルモードで実行されます。 この2つのCPU使用率を監視することで、CPU使用高騰の原因がどこにあるかを確認することが出来ます。
プロセスごとのCPU使用率
プロセスごとのCPU使用率の項目を確認するには、「pidstat」コマンドを利用します。実行方法と応答の例は以下の通りです。
Linux 3.10.0-1062.4.3.el7.x86_64 (linux-server.local) 2020年11月06日 _x86_64_ (8 CPU)
15時04分42秒 UID PID %usr %system %guest %CPU CPU Command
15時04分42秒 0 1188 0.00 0.00 0.00 0.00 2 kworker/2:1H
15時04分42秒 0 1223 0.00 0.00 0.00 0.00 6 abrtd
15時04分42秒 0 1224 0.00 0.00 0.00 0.00 2 abrt-watch-log
15時04分42秒 172 1226 0.00 0.00 0.00 0.00 3 rtkit-daemon
15時04分42秒 0 1228 0.00 0.00 0.00 0.01 1 systemd-logind
15時04分42秒 0 1241 0.00 0.00 0.00 0.00 5 NetworkManager
15時04分42秒 0 1826 0.00 0.00 0.00 0.00 4 kworker/4:1H
15時04分42秒 0 1828 0.00 0.00 0.00 0.01 4 X
15時04分42秒 983 1837 0.00 0.00 0.00 0.00 7 monitor_server
15時04分42秒 0 1838 0.36 0.11 0.00 0.46 2 Site24x7Agent
15時04分42秒 0 2121 5.14 0.33 0.00 5.47 5 java
CPU使用率が高いプロセスを簡単に発見することができます。使用率の推移や高騰の時間・タイミングについても確認すると良いでしょう。
メモリー使用量・ページング
メモリー関連の項目を確認するには、「free」コマンドを利用します。実行方法と応答の例は以下の通りです。
total used free shared buff/cache available
Mem: 8819 2235 5275 52 1308 6271
Swap: 7807 0 7807
- 「Mem」行の「used」「free」
利用可能なメモリー領域をMBで表したものです。 - 「Swap」行のused
ページングに利用された領域(スワップメモリー)です。
コンピュータの動作を速くするためのメモリーの動作として、メモリー上に今後使用するデータや使用したデータなどを保存しておく機能があります。通常のメモリー(物理メモリー)上のデータが一杯になると、メモリー上のデータでしばらく使用していないものをハードディスク上にメモリー用の領域に移動します。ハードディスク上のメモリーは仮想メモリーと呼ばれます。仮想メモリーに配置されたデータが再び必要になると、物理メモリーに戻して再度利用することになります。この、データが物理・仮想メモリー上を行き来することを「ページング」と呼び、ハードディスク上の仮想メモリの領域を「スワップメモリー」と言います。
ハードディスクは物理メモリーよりも処理速度が格段に遅いため、仮想メモリーと物理メモリーを行き来するページングが発生していると、システム全体のパフォーマンスに影響が出やすくなります。
ディスク
ディスク関連の項目を確認するには、「df」コマンドを利用します。実行方法と応答の例は以下の通りです。
ファイルシス サイズ 使用 残り 使用% マウント位置
devtmpfs 4.3G 0 4.3G 0% /dev
tmpfs 4.4G 0 4.4G 0% /dev/shm
tmpfs 4.4G 18M 4.3G 1% /run
tmpfs 4.4G 0 4.4G 0% /sys/fs/cgroup
/dev/mapper/cl-root 50G 19G 32G 38% /
/dev/sda1 1014M 336M 679M 34% /boot
/dev/mapper/cl-opt 142G 4.7G 137G 4% /opt
tmpfs 882M 0 882M 0% /run/user/0
tmpfs 882M 12K 882M 1% /run/user/42
tmpfs 882M 0 882M 0% /run/user/1001
他にも、リソースを監視するコマンドとして「vmstat」コマンドなども利用できます。
上記で紹介したコマンドを実行することにより、Linuxサーバーのパフォーマンスを詳細に確認することが可能になります。
Linuxサーバーのリソース監視をより手軽に実施する方法
コマンドからLinuxサーバーのリソース監視を行う場合、監視対象の装置の台数が増加するにつれて、手動のコマンド実行による監視の負荷が増大していきます。
より効率的にネットワーク機器を管理・監視するには、自動でLinuxサーバーのリソースデータを収集して解析するツールを使用するのがお勧めです。
ManageEngineが提供する統合監視ツールである「OpManager」は、SNMPやSSH・Telnet等を利用してネットワーク機器を自動で監視し、機器のステータスが一目で分かるように可視化します。Linuxサーバーのほか、Windowsサーバー、スイッチ監視、ルーター監視、ポート監視、アプリケーション監視、イベントログ監視機能などが、Webベースのわかりやすい画面で管理できます。ネットワーク監視に関する知識がない方でも操作が可能で、容易に運用できるのが特徴です。
Linuxサーバーのリソース監視の自動化・効率化の方法をお探しの場合は、是非「OpManager」の概要や機能詳細をご覧ください。
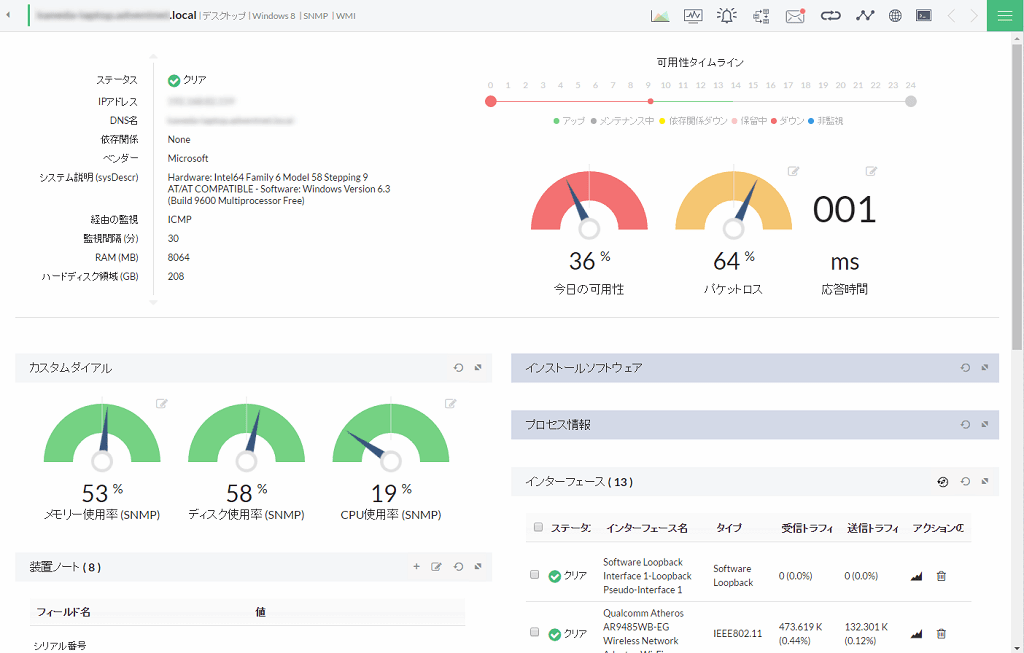
Linuxサーバーから取得したデータをわかりやすく可視化
