リソース監視とは?
リソース監視とは、主にサーバーのCPUやメモリー・ディスクの状態を監視することを指し、性能監視とも呼ばれます。
リソース監視が必要な理由
リソース監視は、システムの障害を未然に防ぎ、安定して稼働させるために非常に重要です。サーバーのリソース状態を把握できていないと、パフォーマンスの低下や高負荷状態といったような障害の兆候を見逃してしまい、やがてはサーバーダウン・システム障害に繋がります。
リソース監視を正しく行えば、障害の兆候を未然に察知し問題が発生する前に修正できるほか、万が一システム障害が発生してしまった場合にも、その原因の特定が容易になり迅速な対応が期待できます。
リソース監視の実現方法
リソース監視は、サーバーに付属するツールやコマンド実行で手動で行うことも不可能ではありません。しかし、リソースの状況を正確にを把握するために監視すべき項目は非常に多く、これらのみで適切な監視を実現するのは困難が伴います。
また手動で24時間365日の監視を続けることは非常に難しいと言えます。監視を行っていなかったタイミングで異常が発生した場合、システム障害が長引いてしまうこともあります。
これを回避するためには、ツールの導入を検討します。OSS(オープンソースソフトウェア)を導入すれば監視が自動化されるため、問題が発生した場合の早期対応も可能になります。
しかしOSSは導入や保守に技術的知識が必要な上、緊急時に適切なサポートを受けられない可能性があり、やはり一定の障壁が残ります。
そのため、多くの管理者がリソース監視を無料でも使えるパッケージソフトウェアで実現しています。
| 手動監視 | オープンソースソフトウェア(OSS) | 有償ツール | |
|---|---|---|---|
| 本体価格 | - | 無料 | 低価格~ |
| サポート | なし | なし または 有料加入のサポートサービス | あり |
| 操作 | OS標準ツール:簡単 コマンド:知識と慣れが必要 | 慣れが必要 | 比較的簡単 |
| データの可視化設定 | Excel等で自作 | 多くの操作が必要 | デフォルトでグラフ表示 |
| カスタマイズ性 | OS標準ツール以上のことを実現するにはコマンド知識が必須 | 自由度が高い(要知識) | 比較的低い |
| 24時間365日監視 | プログラミングが必要 | 〇 | 〇 |
リソース監視を今すぐ簡単にはじめられるツール
ManageEngineが提供するネットワーク統合監視ソフトウェア「OpManager」もパッケージソフトウェアのひとつです。リソース監視に関する多数の項目を自動で監視し、状態を分かりやすく可視化します。
OpManagerはWindows ServerやUnix系サーバーをはじめとした様々なベンダーのサーバーの監視に対応します。監視用のエージェント等のインストールも必要ありません。
OpManagerのリソース監視機能の4つの特徴
リソース監視をはじめとした多くの情報を設定いらずでグラフを用いて可視化します。
収集したデータはレポートとして自動で出力できます。各監視項目に関してあらかじめ設定したしきい値を超えた際のアラート通知機能も備えています。サーバーダウンによるシステム障害の予防や、リソースの買い替え検討などのキャパシティプランニングにも活用できます。
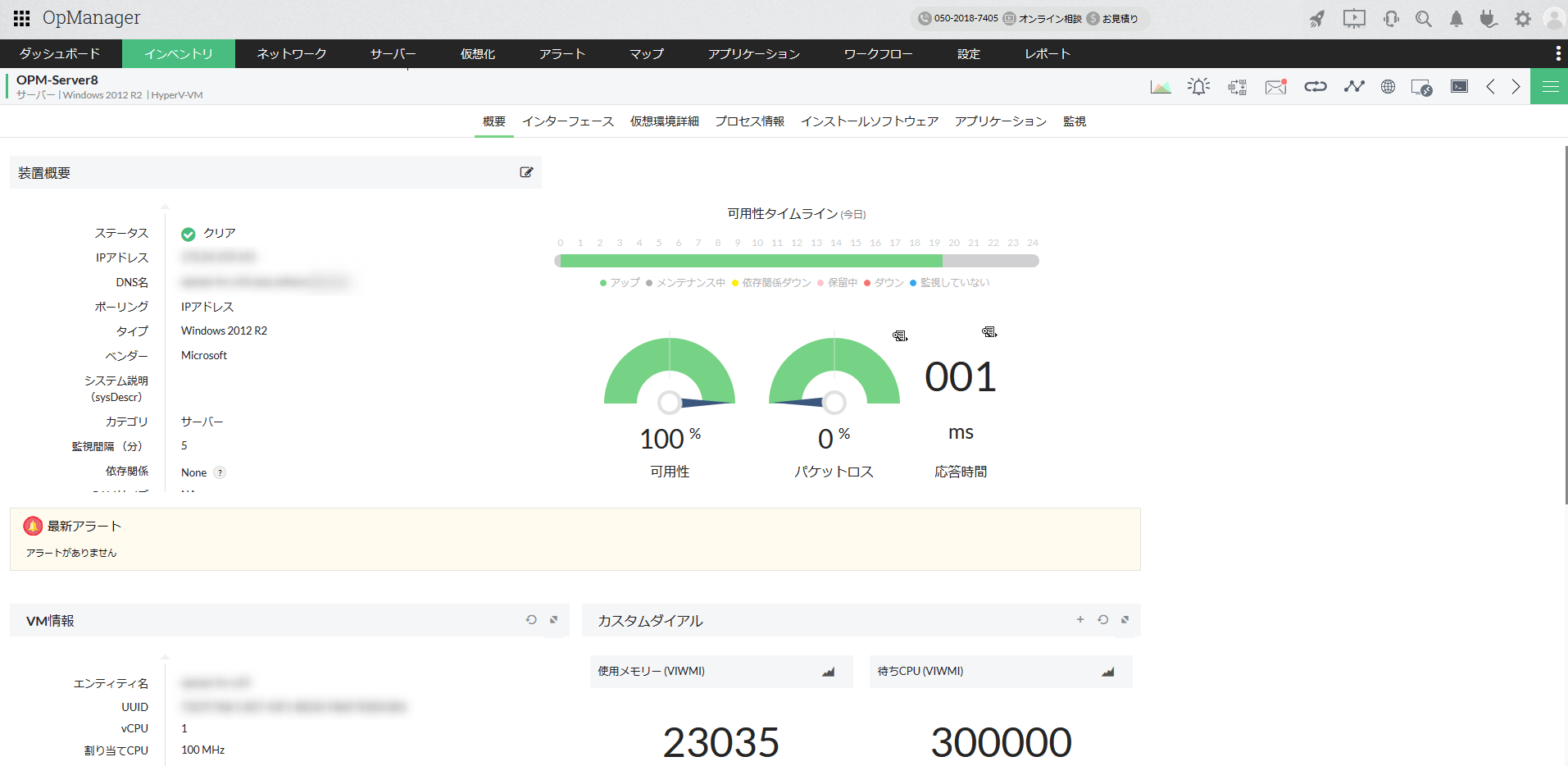
サーバーのスナップショット画面
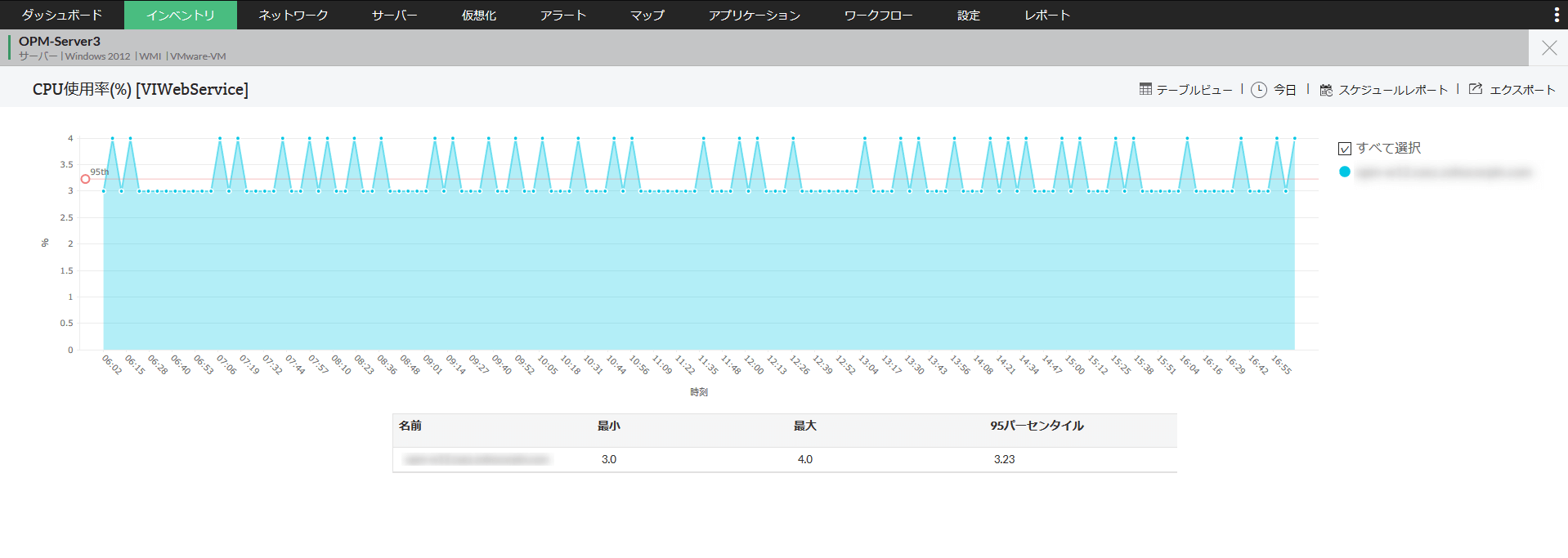
CPU使用率の時系列グラフ
豊富な監視項目
OpManagerを利用したリソース監視では、以下のような25個以上の項目をデフォルトで監視できます。パフォーマンス低下・システム障害が発生した際に、リソースの使用率といった単純な監視では原因が判明しないような場合でも、迅速な原因解明及び対処が行えます。
更に、適切にソースを設定することにより、ユーザーがカスタムで新たな監視項目を設定することも可能です。
| CPUのメトリクス | メモリーのメトリクス | ディスクのメトリクス |
|---|---|---|
|
|
|
しきい値設定とアラート機能
リソースの各監視項目に対してしきい値という許容量を設定することにより、監視項目の値がしきい値を超えた場合にアラートを発報し管理者に通知します。しきい値は段階を分けて設定できます。微小なしきい値違反を検知し、システム障害など大事になる前に対処することが可能です。
更に、アラートと通知プロファイルを関連付けることで、アラート発報の際にメールで個別に管理者に通知したり、あらかじめ設定したコマンドを実行することにより一次対処を自動で行うことができます。
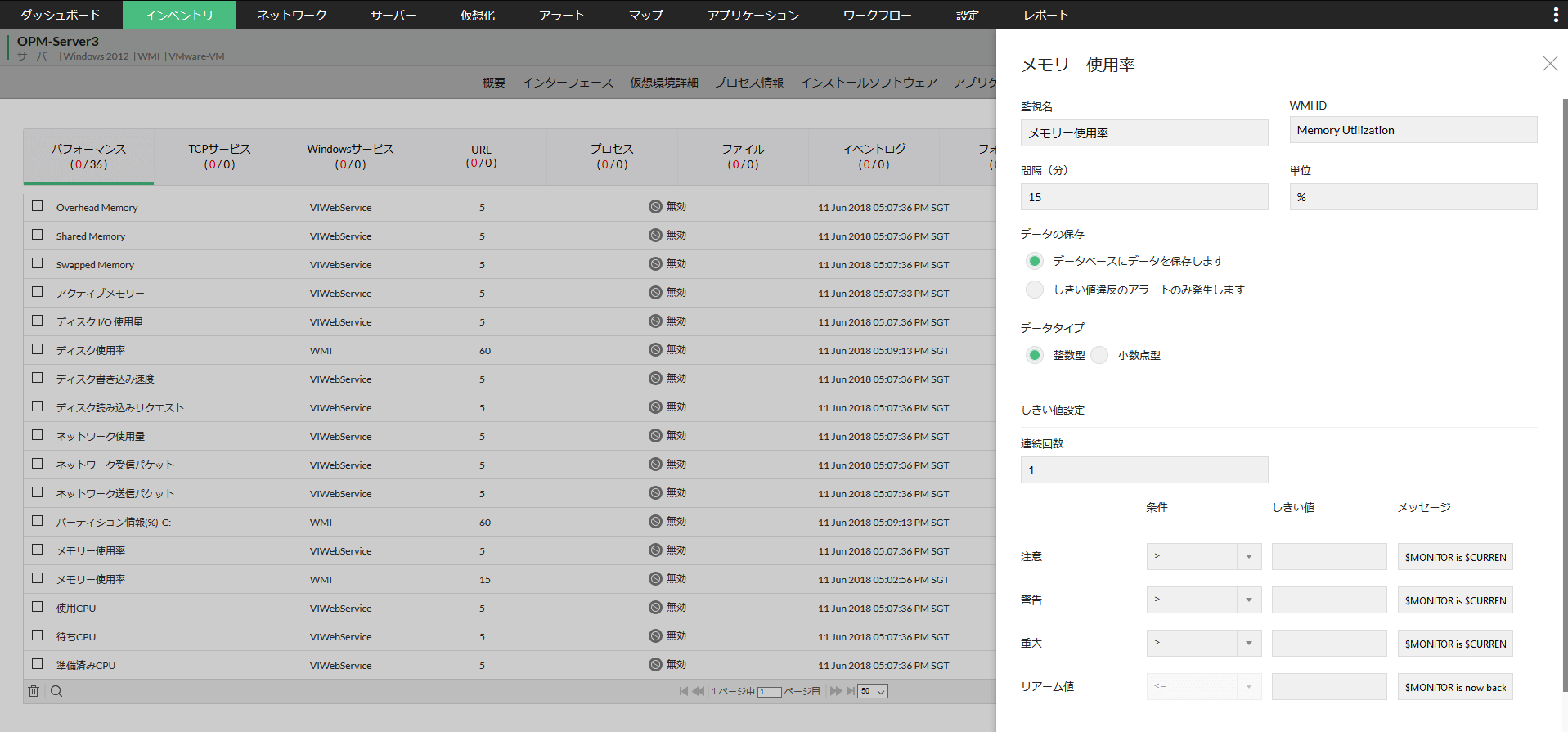
メモリー使用率に関するしきい値設定画面
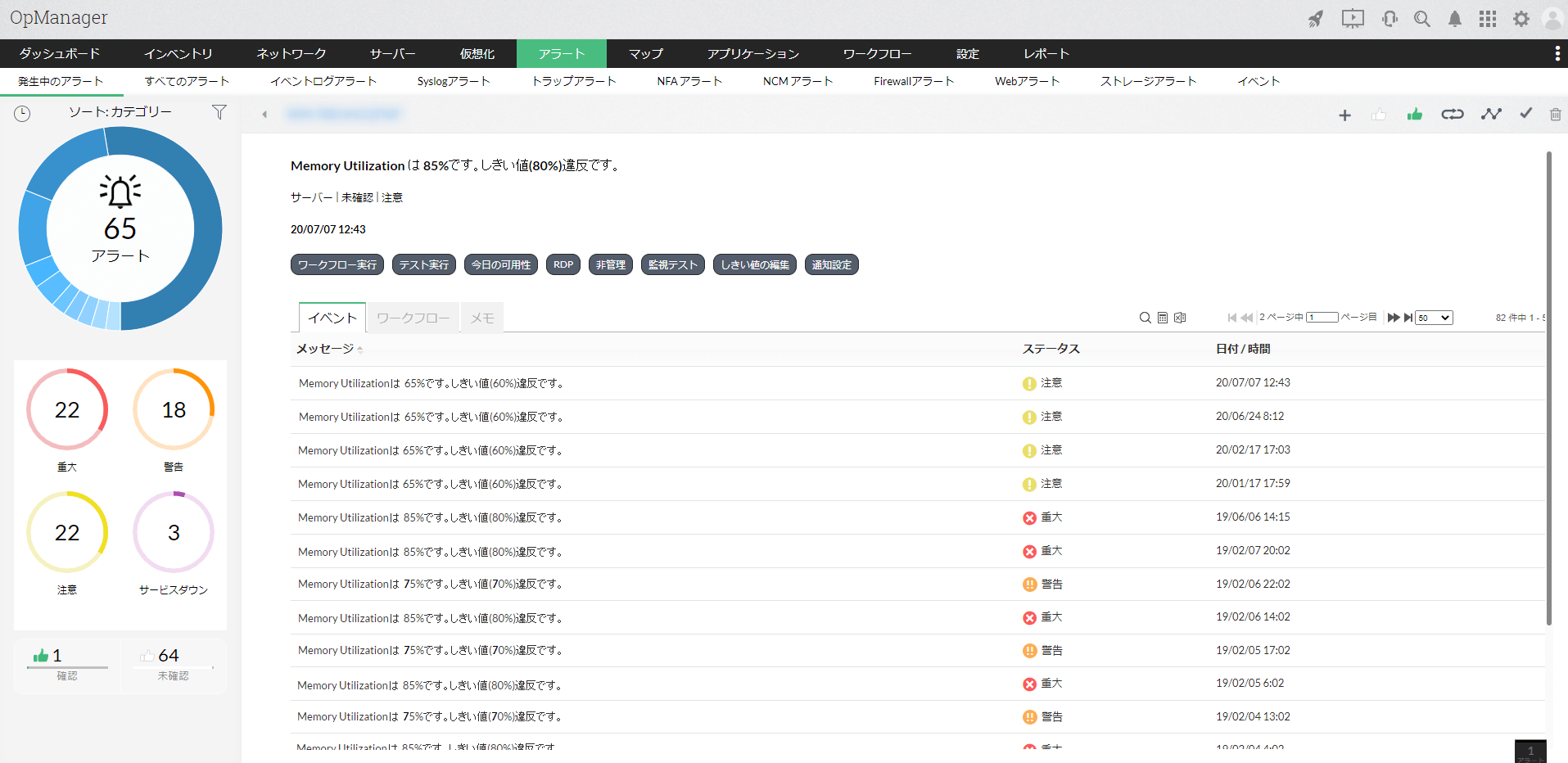
しきい値違反を警報するアラート
リソースの障害を早期解決する診断ツール
リソースの使用率の上昇など何らかの問題が発生した場合、実行中の各プロセスがどれだけリソースを使用しているかを確認することができます。リソースを占有しているプロセスの特定のほか、そのプロセスを終了させることも可能であり、問題の原因特定や早期解決に役立ちます。
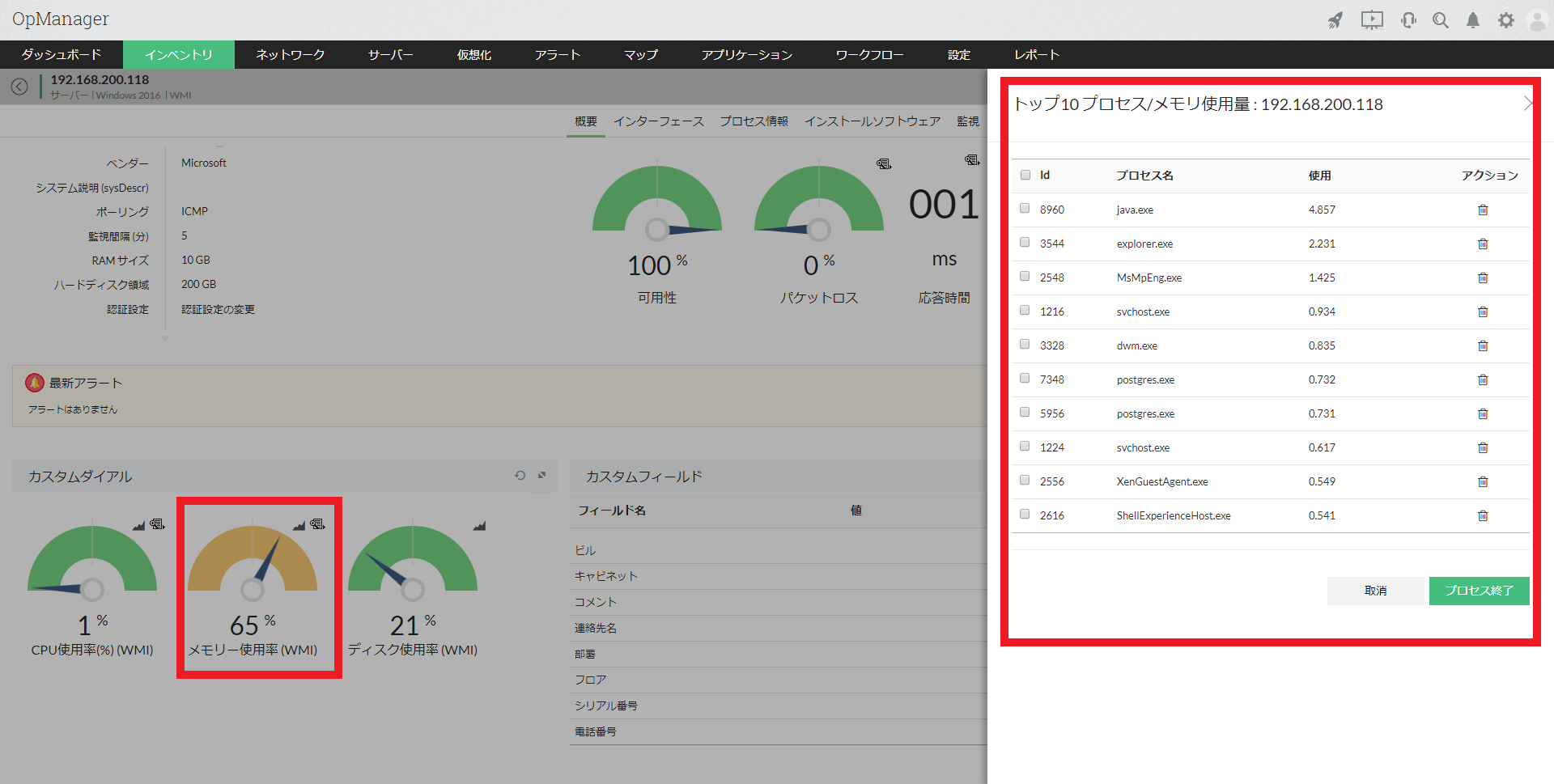
プロセス毎のメモリ使用率の診断
パフォーマンス分析のためのレポート出力機能
リソース監視の各値が時系列に整理し、グラフで分かりやすく可視化したレポートを自動で作成し出力することが可能です。出力できるレポートの種類は様々で、特定の装置の情報に特化したものや、全サーバーのCPU使用率トップ10といった統計的なレポートまで出力可能です。
サーバーのパフォーマンスが時系列でわかりやすく把握できるため、リソース増強の検討や、トレンドの分析など様々な用途に利用できます。
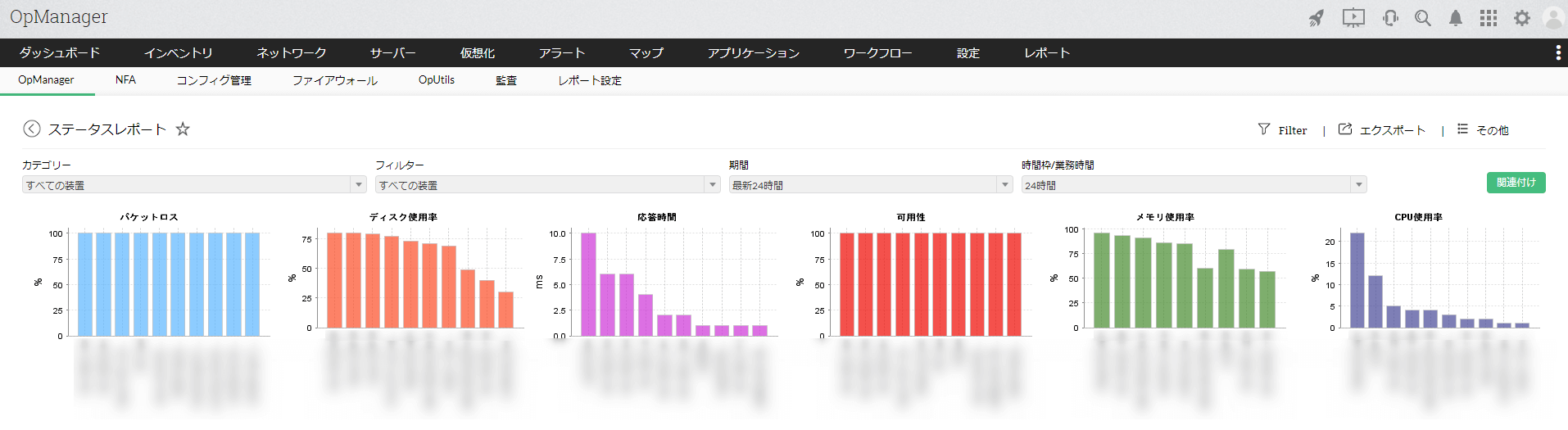
サーバーリソースの概要レポート
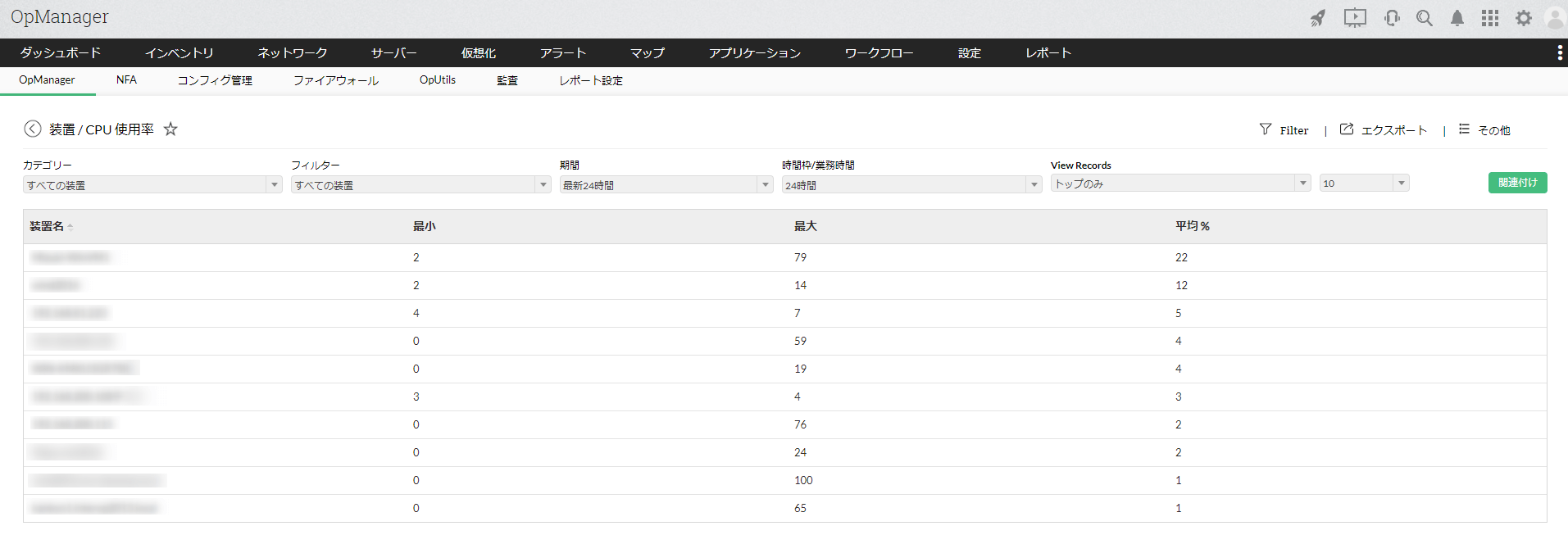
CPU使用率のトップ10レポート
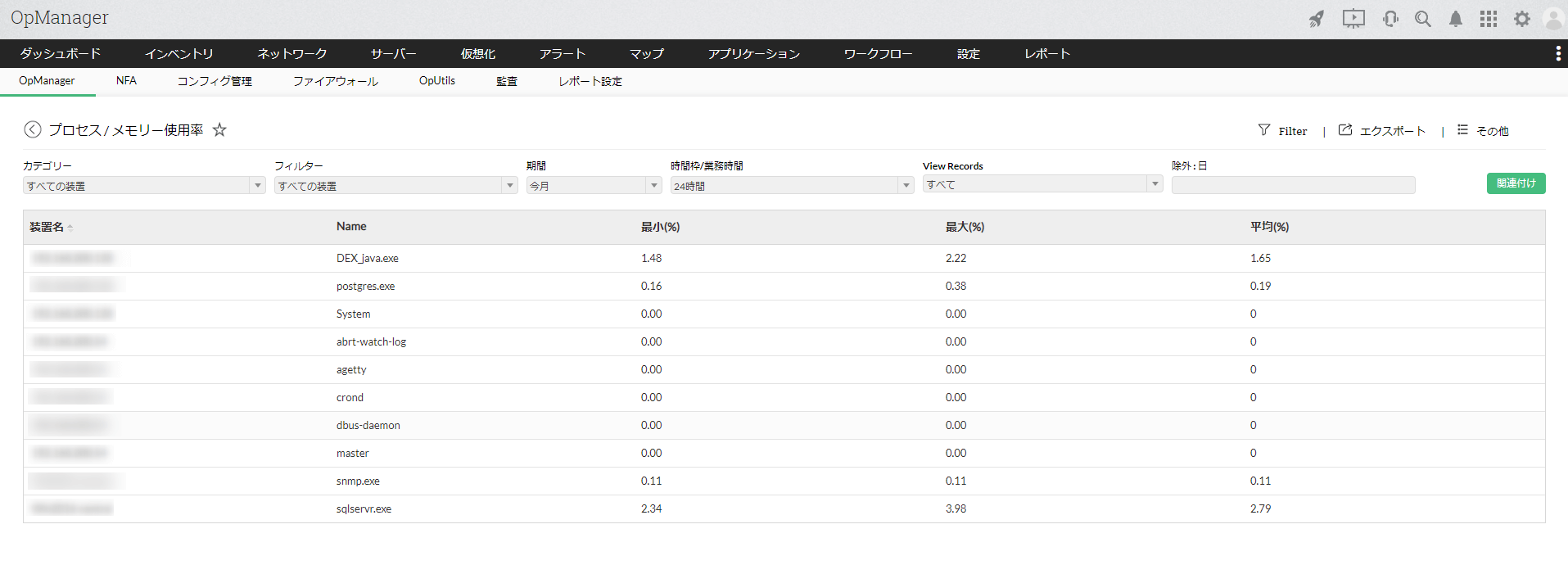
プロセス単位のメモリー使用率レポート